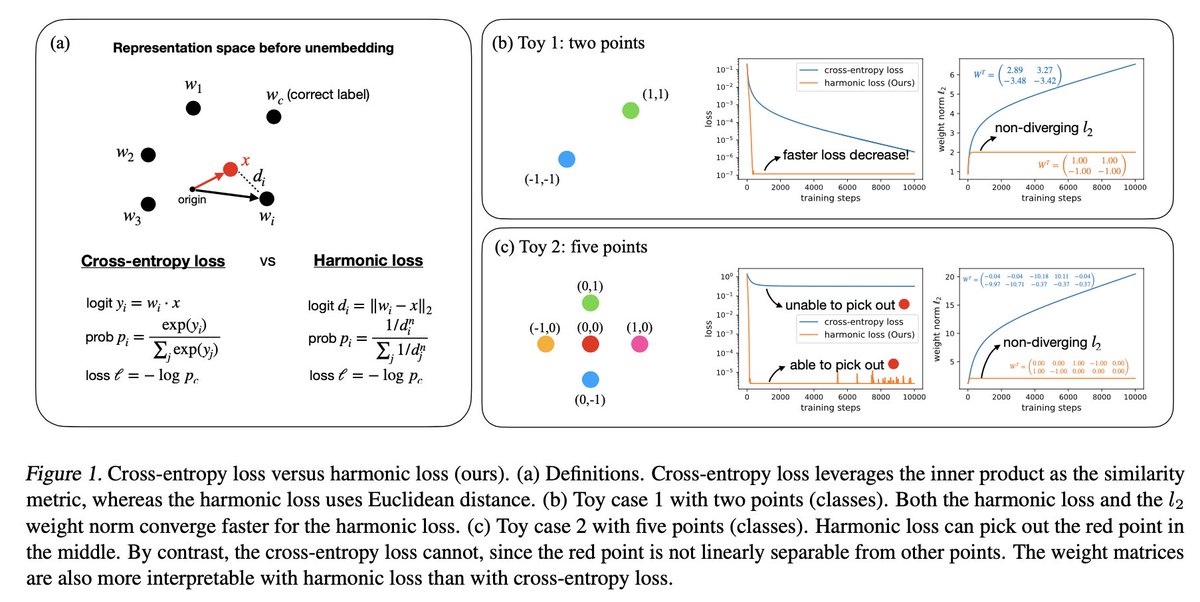
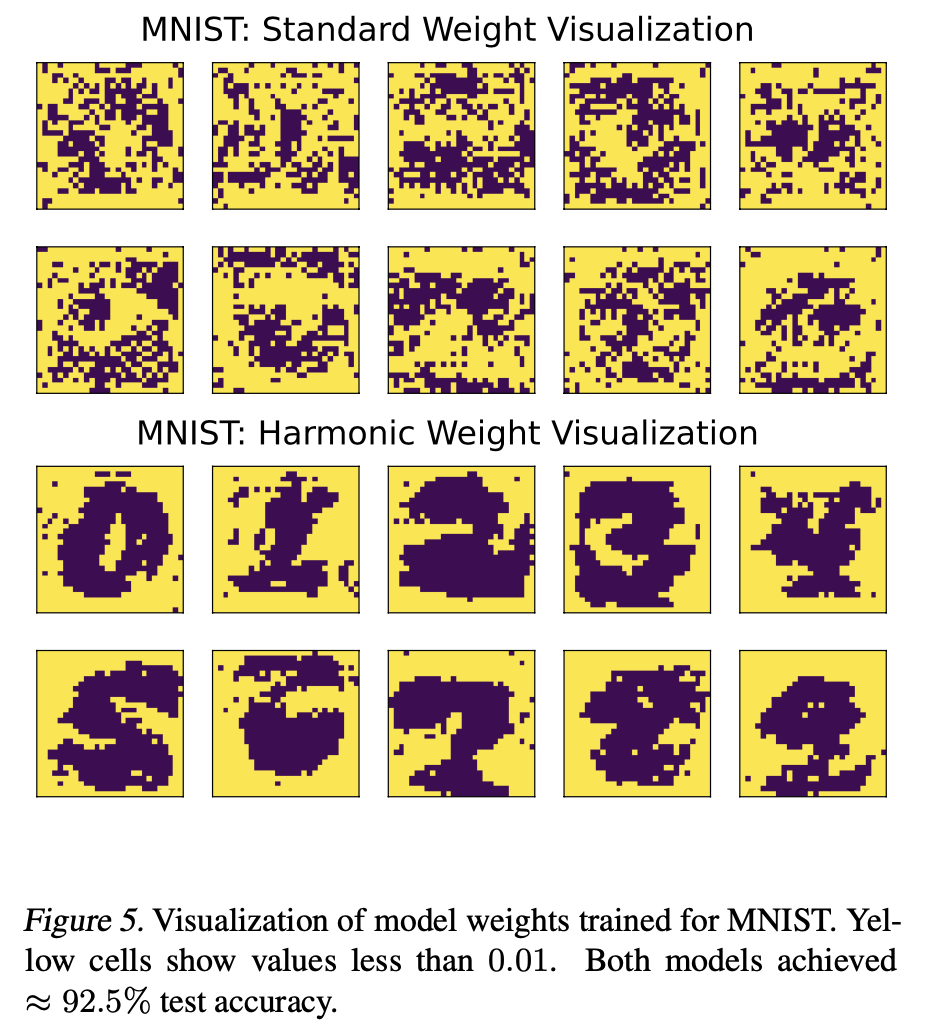
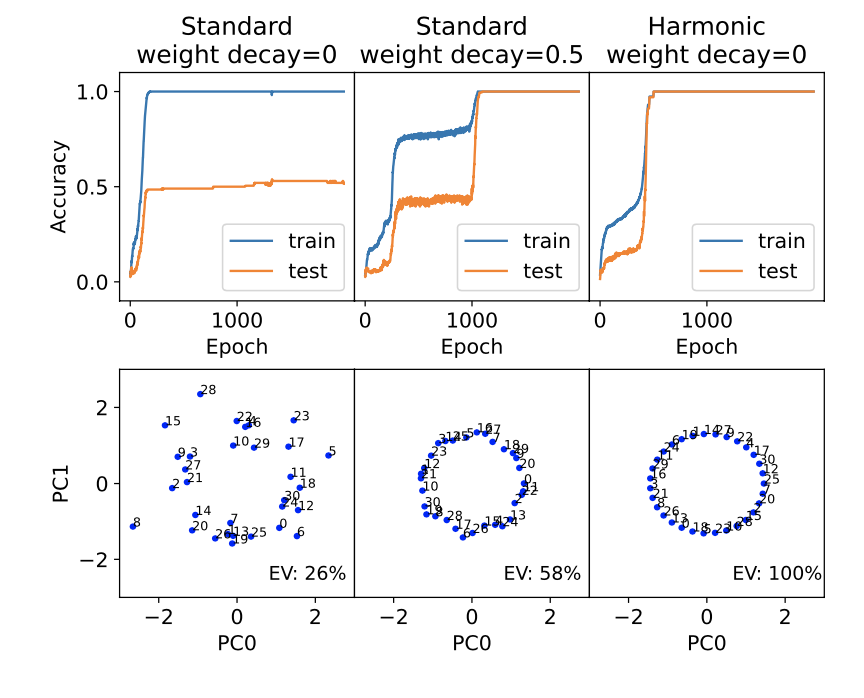
1/9 🚨 New Paper Alert: Cross-Entropy Loss is NOT What You Need! 🚨
We introduce harmonic loss as alternative to the standard CE loss for training neural networks and LLMs! Harmonic loss achieves 🛠️significantly better interpretability, ⚡faster convergence, and ⏳less grokking!

GIF