Pinned

Something we have been heads-down working on for a while:
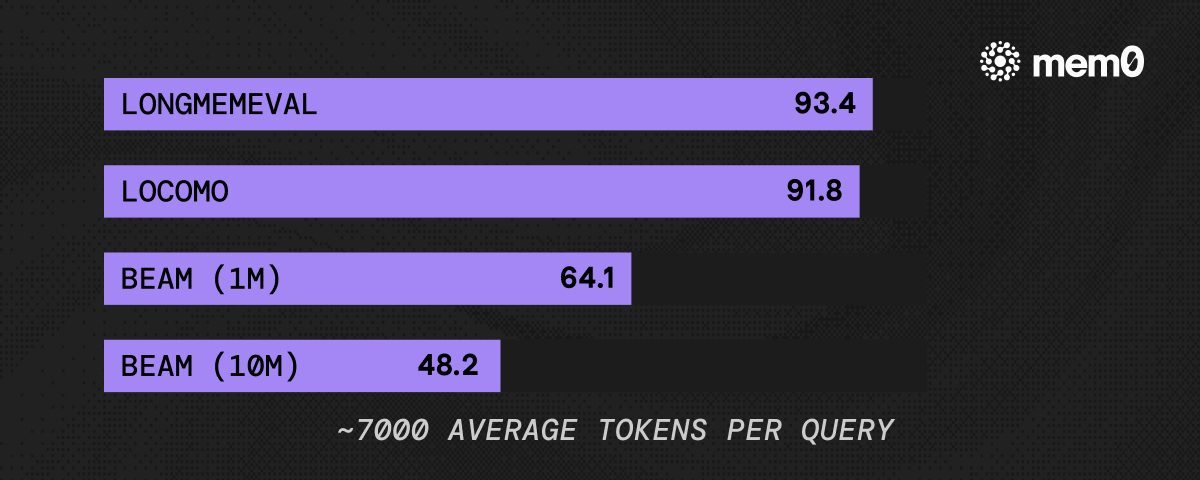
Most memory systems burn today ~25K tokens/query loading context. That's fine at small scale but brutal in production.
We just shipped a new token-efficient memory algorithm that hits competitive numbers on all relevant