Sergey Edunov
101 posts


Sergey Edunov
@edunov
CTO @ Genesis Molecular AI.
Ex: AI Research Director @ Meta
Joined March 2010
- People seem to over-index on the 15T number after Llama 3. While the number matters, what is even more important is the quality and diversity of those tokens. If there was a good way to measure those, that would have been an impressive result to report.Llama3 was trained on 15 trillion tokens of public data. But where can you find such datasets and recipes?? Here comes the first release of 🍷Fineweb. A high quality large scale filtered web dataset out-performing all current datasets of its scale. We trained 200+ ablation
- Fascinating, how entire LLM industry is chasing ELO score on lmsys, just recently it was Open LLM leaderboard and MMLU, and still around those who remember the days of GLUE and SuperGLUE. Meanwhile Goodhart's law never gets old: "When a measure becomes a target, it ceases to be
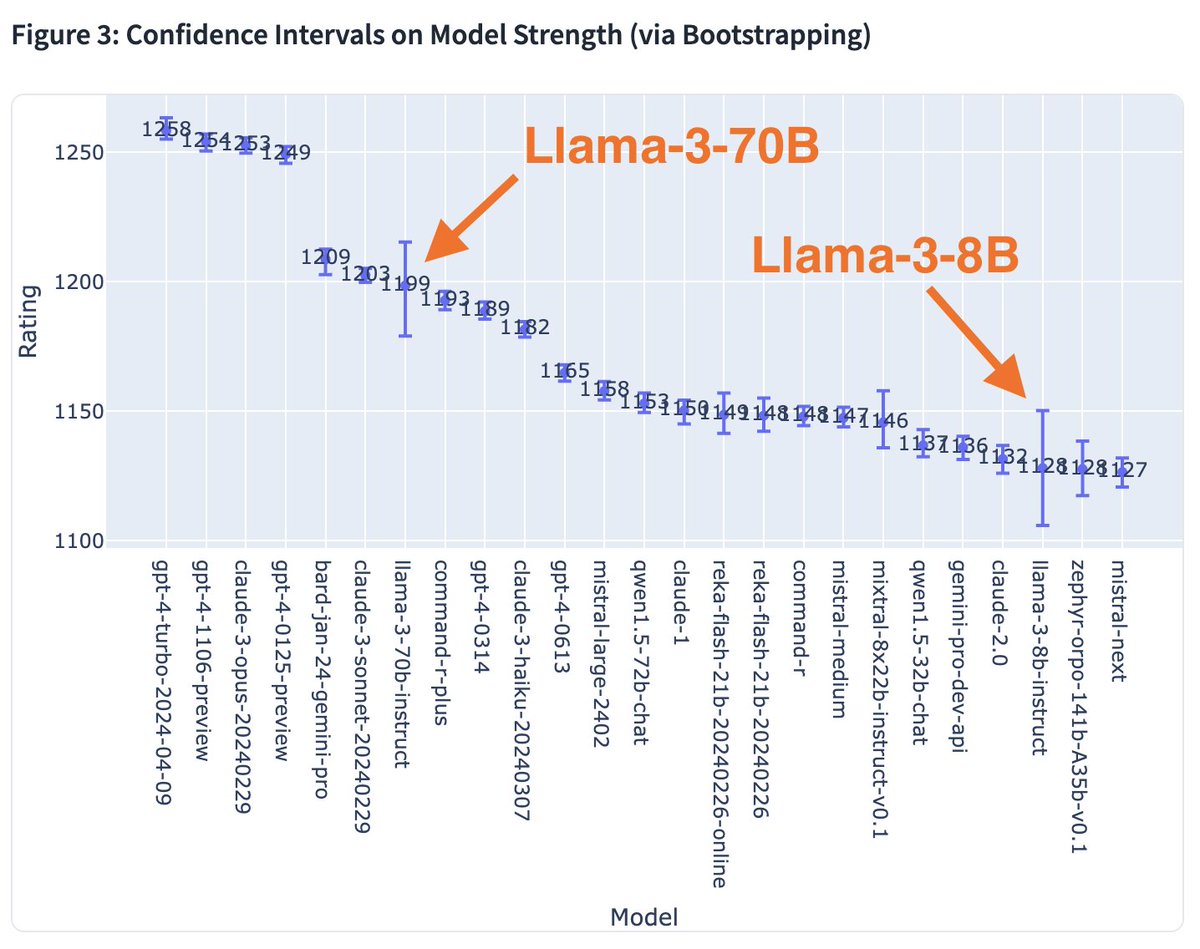
- The real king is still training 💪😝 But go go go 70B and 8B!Early 1K votes are in and Llama-3 is on FIRE!🔥The New king of OSS model? Vote now and make your voice heard! Leaderboard update coming very soon.
- There are many ways a very large and powerful model can be useful, even if no one can run it locally today: Distillation -- think about all recent results people show distilling GPT-4 outputs and training smaller models on those, how much more can be done if the teacher modelI really love Meta’s open-source focus, but I doubt many of us will leverage such big models. None of us will run Llama3 400B locally 😅 Using APIs stays the way most of us will interact and work with LLMs. But Llama-3 8B or even 70B is quite cool, haha! Still, open sourcing

- Llama 3 has arrived! Taaa-daaam!
- How come long context adaptions of Llama 3 that are being released only report performance on long context benchmarks? Do we assume that context extension happens for free without impacting model performance? Show us your MMLU, GSM8K, ARC-C and DROP!
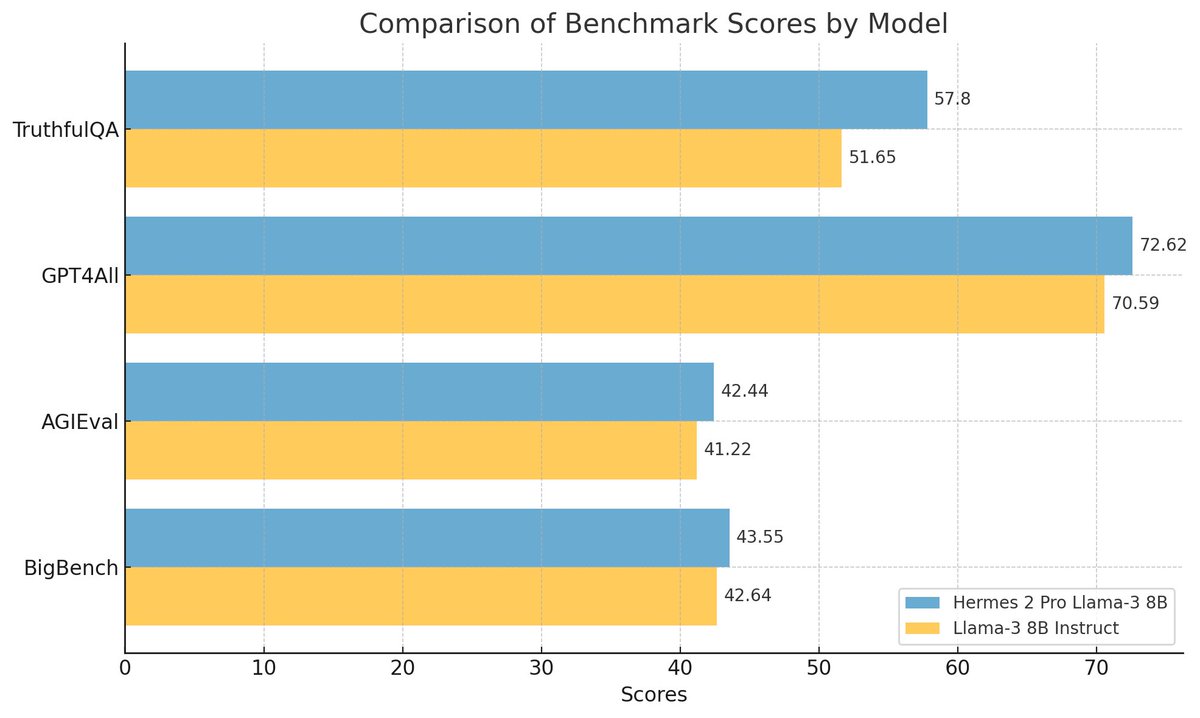
- Announcing Hermes 2 Pro on Llama-3 8B! Nous Research's first Llama-3 based model is now available on HuggingFace. Hermes Pro comes with Function Calling and Structured Output capabilities, and the Llama-3 version now uses dedicated tokens for tool call parsing tags, to make
- MMLU is particularly tricky. - how do you prompt matters a lot - changes in the order of answers in 5-shot examples matter - whether you use logits or model generations matters - do you micro-average or macro-average matters - it is also quite noisy It all works out okayHow should you prompt an LM for MMLU? (You could say MMLU is contaminated/saturated and we should just use vibes, but that’s a separate conversation. As long as people are bragging about their MMLU scores, we should make sure we know what these scores mean). Two extremes:
- In our past lives we did machine translation 😅 Happy to share that this work is now published in Nature.
 It is been a long team journey, and our NLLB work is now published in Nature. Proud of having being part of successfully scaling translation to 200 languages: nature.com/articles/s4158…
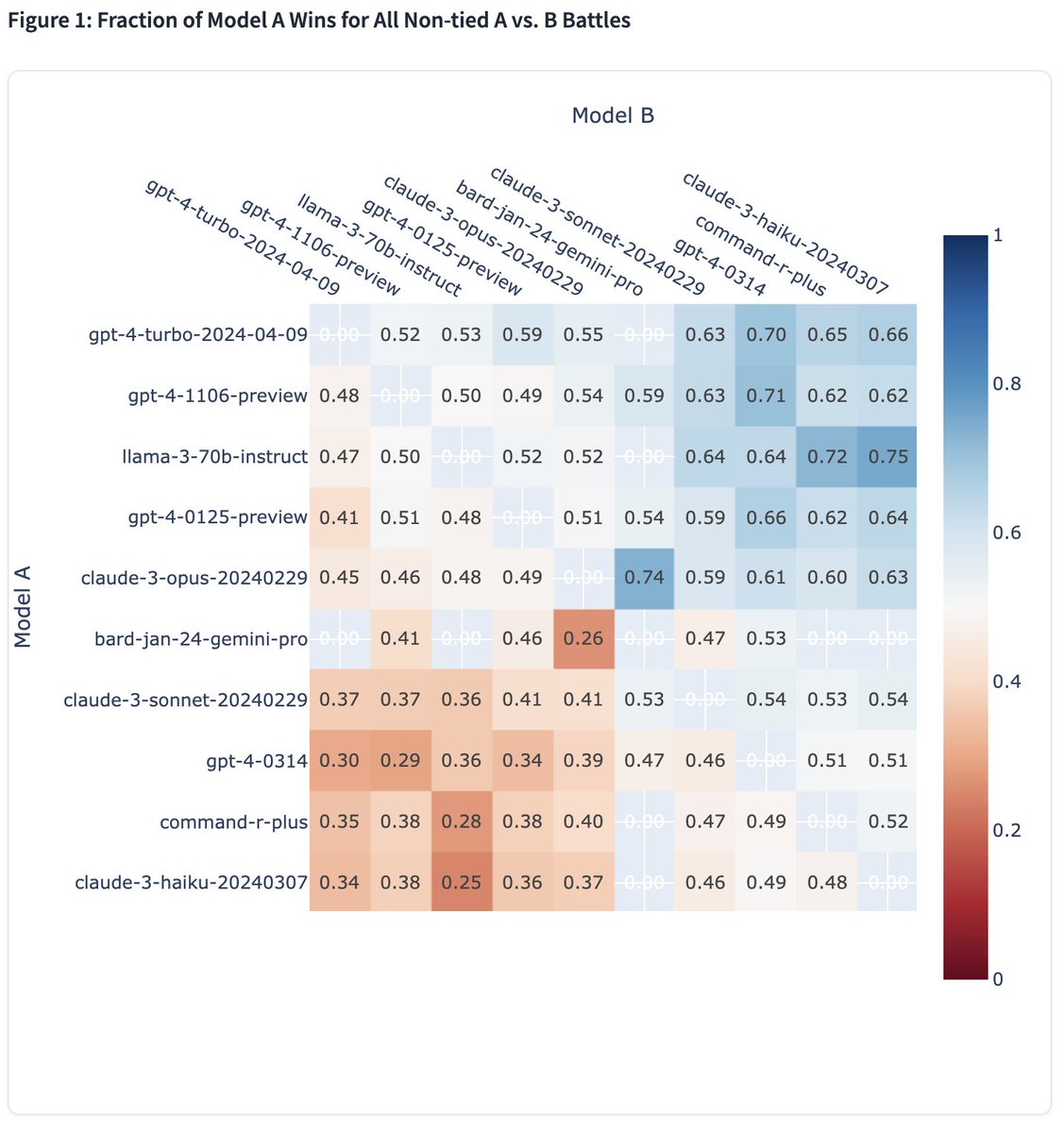
It is been a long team journey, and our NLLB work is now published in Nature. Proud of having being part of successfully scaling translation to 200 languages: nature.com/articles/s4158… - So so so excited about these resultsReplying to @arenaMoreover, we observe even stronger performance in English category, where Llama 3 ranking jumps to ~1st place with GPT-4-Turbo! It consistently performs strong against top models (see win-rate matrix) by human preference. It's been optimized for dialogue scenario with large

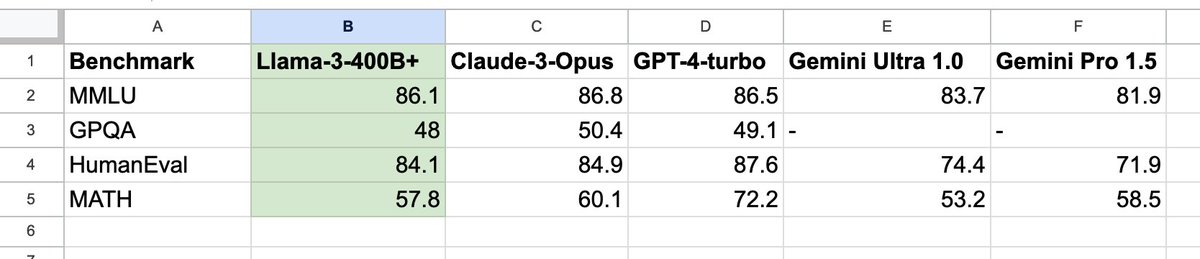
- Llama 3 to the moon 🚀 😉The upcoming Llama-3-400B+ will mark the watershed moment that the community gains open-weight access to a GPT-4-class model. It will change the calculus for many research efforts and grassroot startups. I pulled the numbers on Claude 3 Opus, GPT-4-2024-04-09, and Gemini.