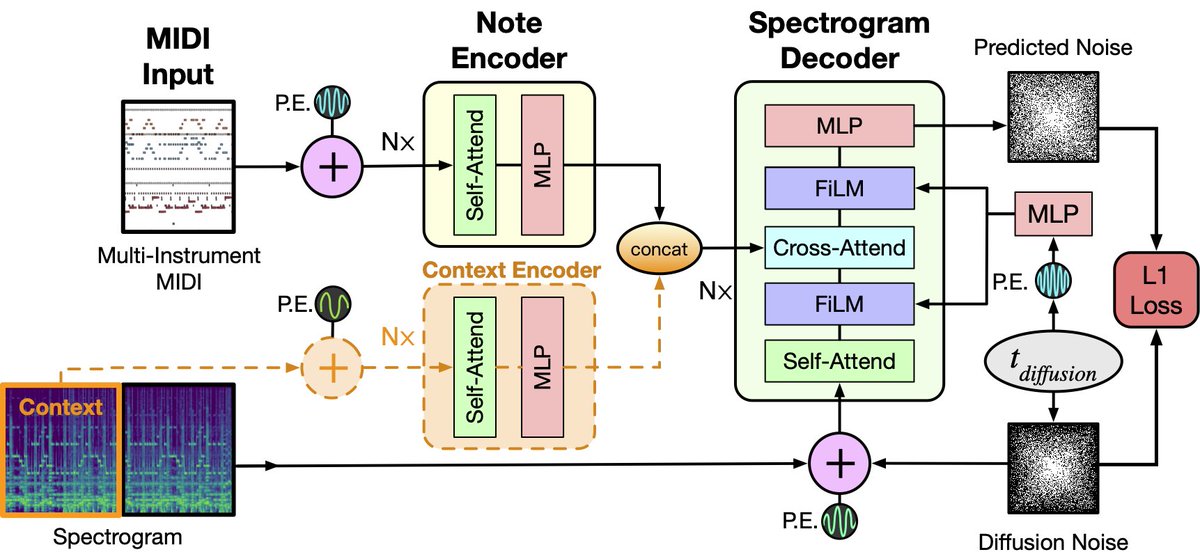
Diffusion for music synthesis!
We trained a “notes2audio” pipeline to synthesize audio from multi-instrument MIDI notes.
Listen 🔊: g.co/magenta/spec-d…
Play 🎼: g.co/magenta/spec-d…
Code 👩💻: g.co/magenta/spec-d…
Read 📝 : arxiv.org/abs/2206.05408
1/