Thrilled to share that I will be joining the University of Wisconsin @WisconsinCS as an assistant professor in January 2021. Incredibly grateful to all of the wonderful people who have supported me on this journey!
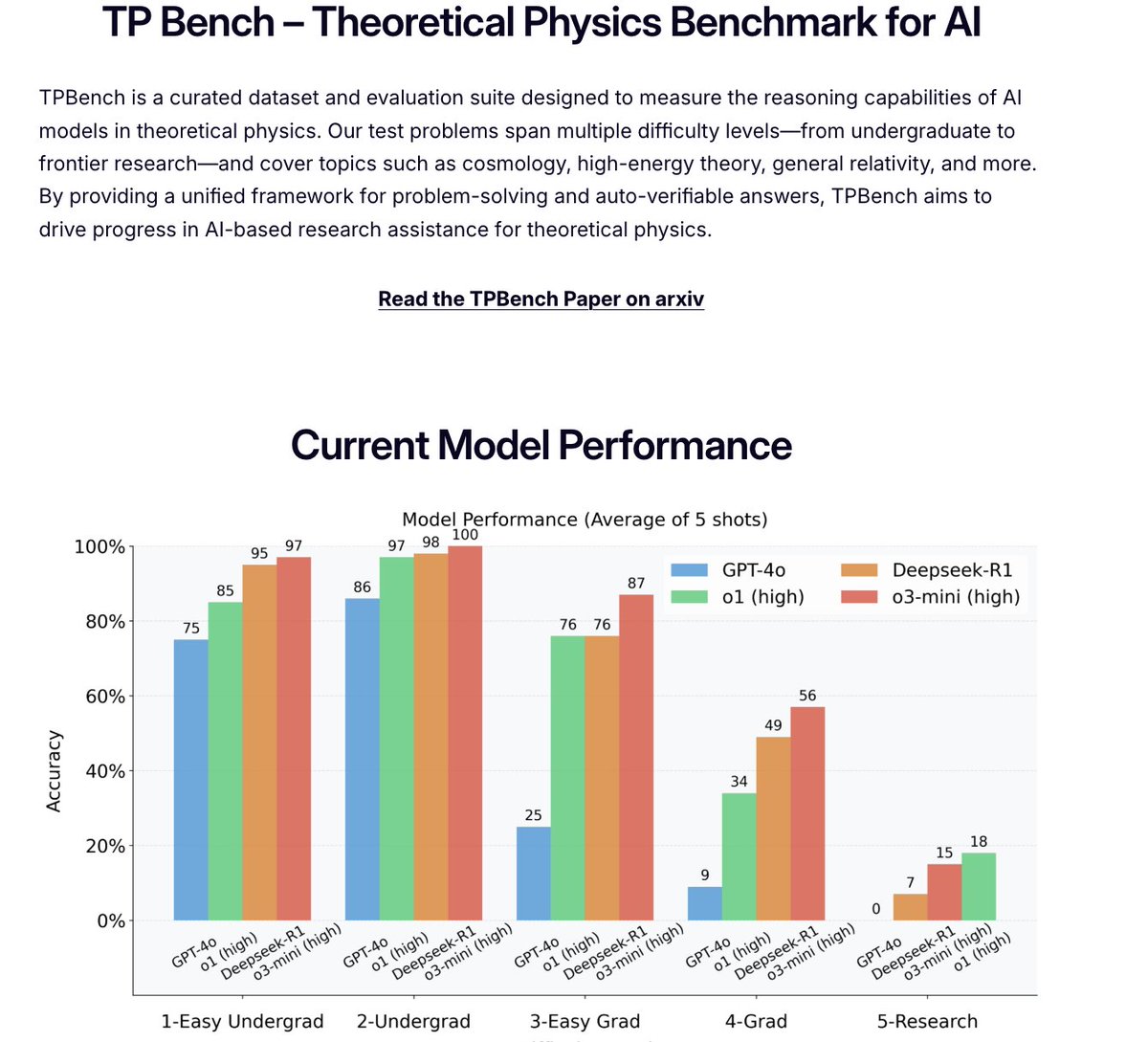
Tired of evaluating frontier models on contrived math olympiad problems? We have a cure! Try your models on our new benchmark for theoretical physics TPBench.
Distillation is an important process, but why limit ourselves to distilling models into models, instead of into other objects?
In new work from my group, we distill model capabilities into programs—a spotlight at #neurips2024.
Annotating your data with state-of-the-art large language models can be costly and opaque. What can we do about this? Simple idea: instead of prompting LLMs for labels, we distill them into programs you can run locally for free. Introducing Alchemist, a Spotlight at #NeurIPS2024!
Generative models are awesome at producing data, and weak supervision is great at efficient labeling. Can we combine them to get cheap datasets for training or fine-tuning?
Excited to present our #ICLR2023 paper "Generative Modeling Helps Weak Supervision (and Vice Versa)"
First up at #NeurIPS2024 from our group, our work on labeling via programmatic distillation (a spotlight!). Label your data orders of magnitude faster and cheaper — come join us today at Poster Session 2 East for a demo!
Come by #ICLR2024 Session 2 on Tuesday to see our work using representation editing to make foundation models robust! No fine-tuning, no additional data, no problem.
arxiv.org/pdf/2309.04344
Join us tomorrow at @iclr_conf for our work on automating dataset construction for diverse data types arxiv.org/pdf/2112.03865…
Poster Session 12, Thursday evening
Excited to share that our work on improving the robustness of foundation models, without training or data, will be at @iclr_conf !
Longer version of our paper that won best paper honorable mention at the NeurIPS R0-FoMo workshop last month.
This Post is from an account that no longer exists. Learn more
Fun new work from our group spearheaded by @nick11roberts: we build new hybrid mixed-architecture models from pretrained model building blocks!
arxiv.org/pdf/2406.00894
Feedback and comments appreciated!
So many new LLM architectures (Mambas🐍, Transformers🤖,🦙,🦔, Hyenas🐺,🦓…), so little GPU time to combine them into hybrid LLMs…
Good news! Today we release Manticore, a system for creating **pretrained hybrids** from pretrained models! 👨🌾🦁🦂
arxiv.org/pdf/2406.00894
1/n
What enables a strong model to surpass its weaker teacher?
🚀 Excited to share our ICLR 2025 paper: "Weak-to-Strong Generalization Through the Data-Centric Lens"! 🧵
Excited to receive an American Family Funding Initiative Award for my group's work on data-efficient customization for large pretrained models! Thanks to the Data Science Institute (DSI) and @amfam!