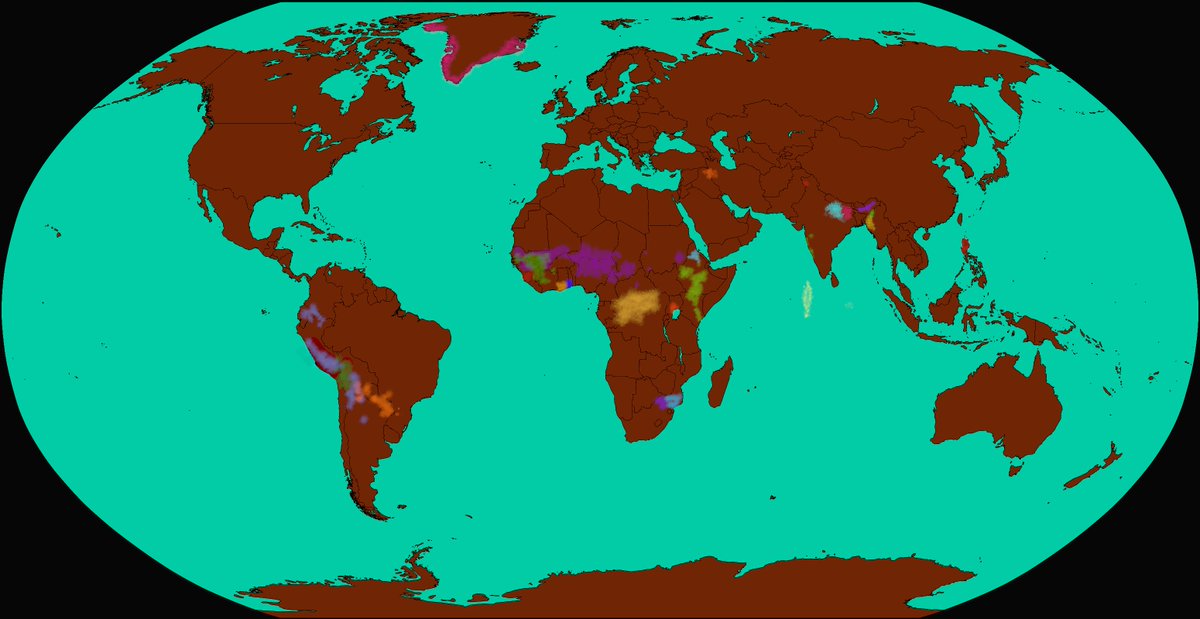
How many languages can we support with Machine Translation? We train a translation model on 1000+ languages, using it to launch 24 new languages on Google Translate without any parallel data for these languages.arxiv.org/abs/2205.03983 Technical 🧵below: 1/18