It seems GPT‑OSS is very prone to hallucinations … check out our RLCR paper to see how we trained reasoning models to know what they don't know. Website 🌐 and code 💻 out today! rl-calibration.github.io 🚀
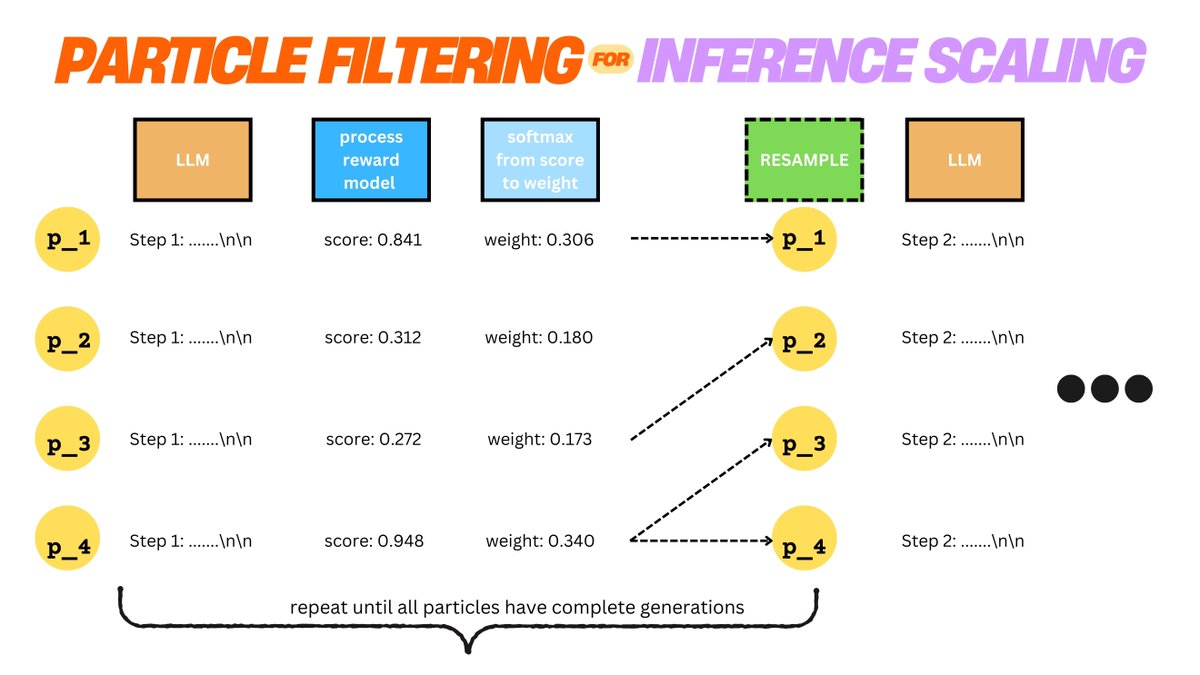
[1/x] can we scale small, open LMs to o1 level? Using classical probabilistic inference methods, YES! Joint @MIT_CSAIL / @RedHat AI Innovation Team work introduces a particle filtering approach to scaling inference w/o any training! check out …abilistic-inference-scaling.github.io
had a great time giving a talk about probabilistic inference scaling and the power of small models at the IBM Research ML Seminar Series - the best talks end with tons of questions, and it was great to see everyone so engaged : )
🚨New Paper!🚨
We trained reasoning LLMs to reason about what they don't know.
o1-style reasoning training improves accuracy but produces overconfident models that hallucinate more.
Meet RLCR: a simple RL method that trains LLMs to reason and reflect on their uncertainty --
Excited to see our Beyond Binary Rewards paper referenced in OpenAI’s latest work on hallucinations - it's important to incentivize models to express uncertainty, not just guess!
New research explains why LLMs hallucinate, through a connection between supervised and self-supervised learning. We also describe a key obstacle that can be removed to reduce them. 🧵openai.com/index/why-lang…
🚀🚀thank you to @rohanpaul_ai for sharing! 🚀🚀
check out …abilistic-inference-scaling.github.io for more information on this cool inference scaling technique and how it can be leveraged to transform smaller, open models into more powerful reasoning agents! 🧠
Qwen2.5-Math-7B-Instruct can scale to o1 level accuracy in only 32 rollouts.
This paper's methods has a 4–16x better scaling rate over our deterministic search counterparts.
Current inference-time scaling often relies on imperfect reward models that cause “reward hacking.”
just moved to SF to join @AbridgeHQ, working on AI and product! thrilled to be here working with amazing people in the health tech space :) let me know if you’re in the area - would love to chat!
super excited to be working with such awesome people towards such a genuine mission :))
Age-restricted adult content. This content might not be appropriate for people under 18 years old. To view this media, you’ll need to log in to X. Learn more
Hello everyone! We are quite a bit late to the twitter party, but welcome to the MIT NLP Group account! follow along for the latest research from our labs as we dive deep into language, learning, and logic 🤖📚🧠
our new work w awesome @RedHat collaborators on novel inference scaling techniques - check out bit.ly/3CHs1Zz for more on how to scale small LMs to o1 performance! 🚀🚀🚀
Can we use classical probabilistic inference methods to scale small LMs to o1 level? 🤔 @MIT_CSAIL and Red Hat AI Innovation teams explore: bit.ly/3CHs1Zz
🚨This week's top AI/ML research papers:
- GSPO
- Diffusion Beats Autoregressive in Data-Constrained Settings
- Gemini 2.5 Pro Capable of Winning Gold at IMO 2025
- Rubrics as Rewards
- Deep Researcher with Test-Time Diffusion
- Learning without training
- Stabilizing Knowledge,
[4/x] Without ANY training, we are able to scale a 1) Llama 1B model to almost reach Llama 70B, 2) Llama 8B model to reach GPT-4o, and 3) Qwen 7B Math model to reach o1! Our method is elegant, simple and could even have novel applications for downstream training applications!