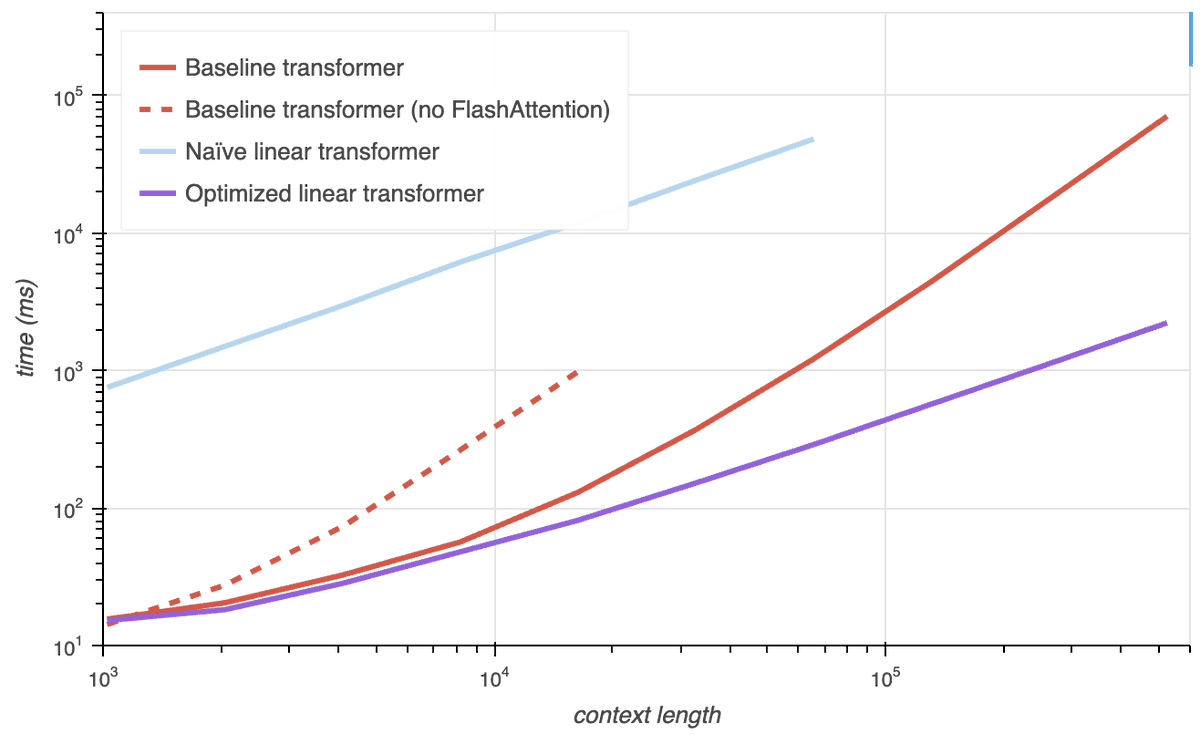
The end of the transformer era marches slowly closer: we trained a completely attention-free foundation model at the 14B scale for only $4,000.
The performance matches other models of similar scale, including transformers and hybrid models.


Today we are releasing Brumby-14B-Base, the strongest attention-free base model around.
manifestai.com/articles/relea…