🗞New Paper🗞
🤖🧪Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning 🧪🤖
Huge thanks to @neilbband* as well as @clarelyle, @AidanNGomez, @tom_rainforth, @yaringal, and @OATML_Oxford !
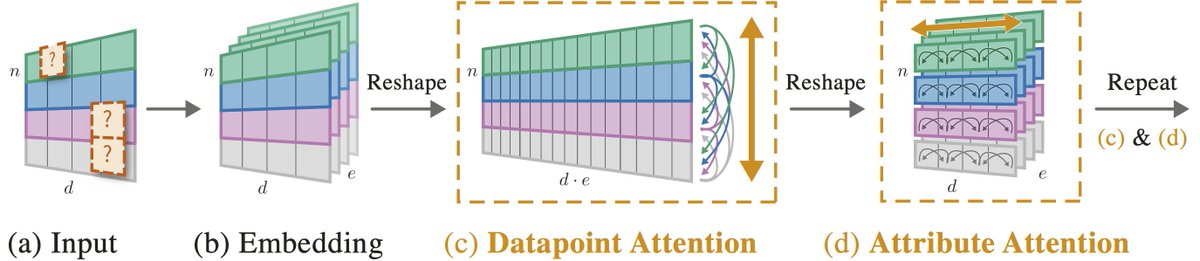
Introducing 🚀Non-Parametric Transformers🚀 1/