Pinned

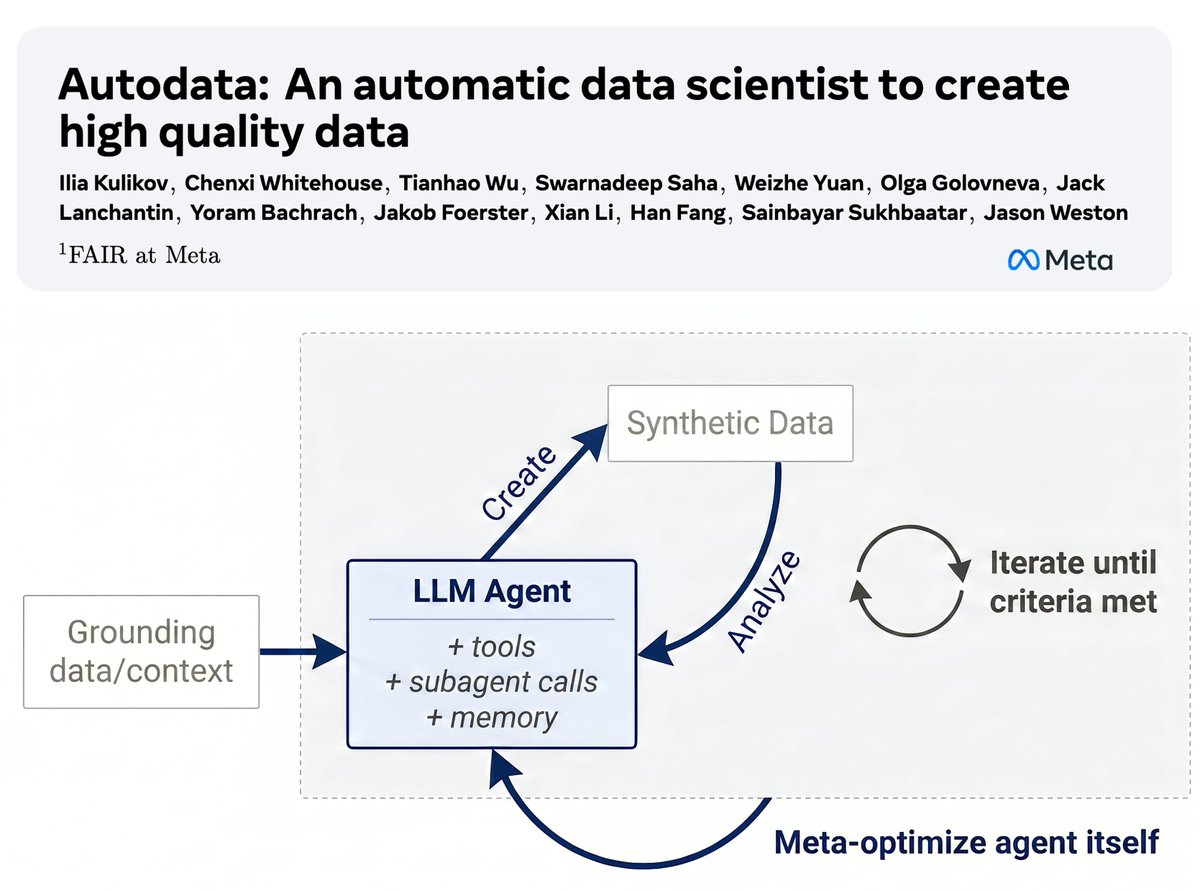
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model