Pinned

'Autoresearch', but for theoretical science?
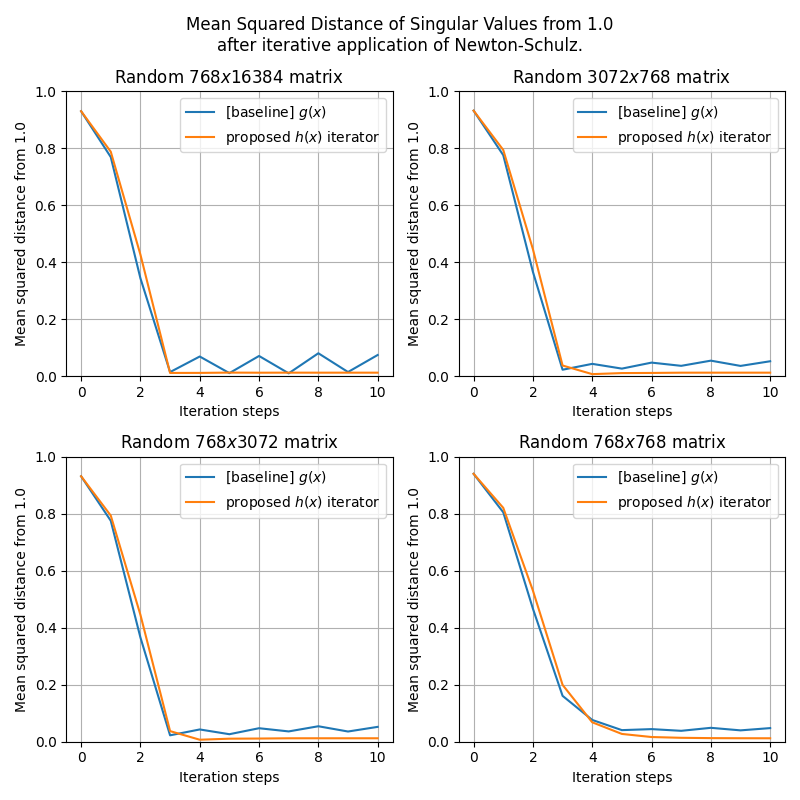
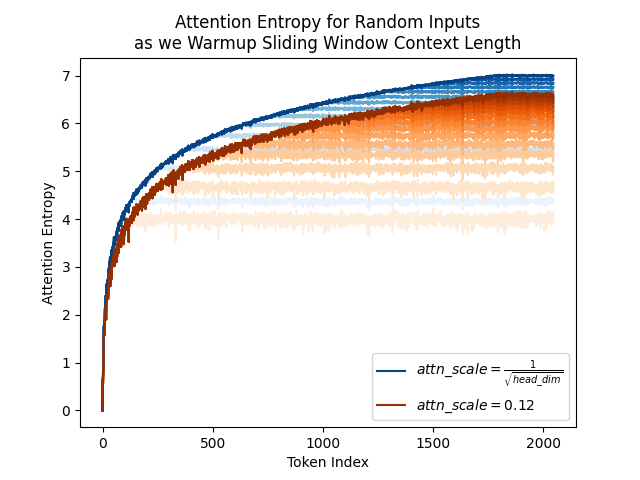
I formalized my blog posts on steepest descent convergence bounds and hyperparameter scaling laws in Lean using Codex.
This started as an art project, but I ended up having similar (almost exactly the same) results as prior work








Excited results!!
I was also working on this direction a few months back but only managed to reach the necessary step before this. I got similar results to @dakovalev1 's, but without the need to go back-and-forth between dual norms and the frobenius norm which makes the