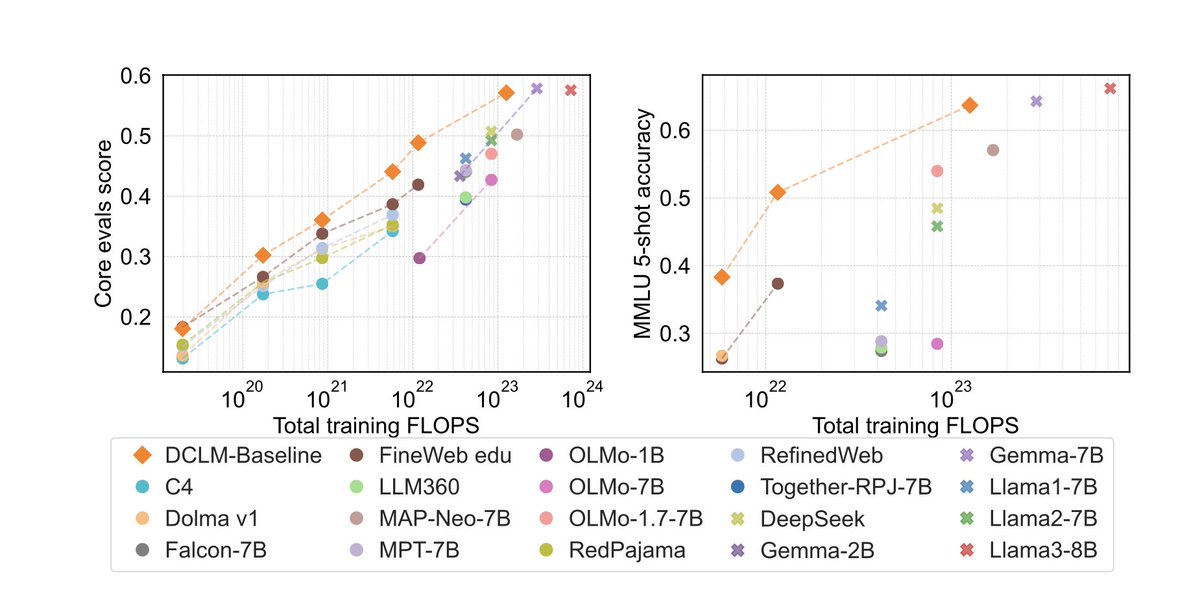
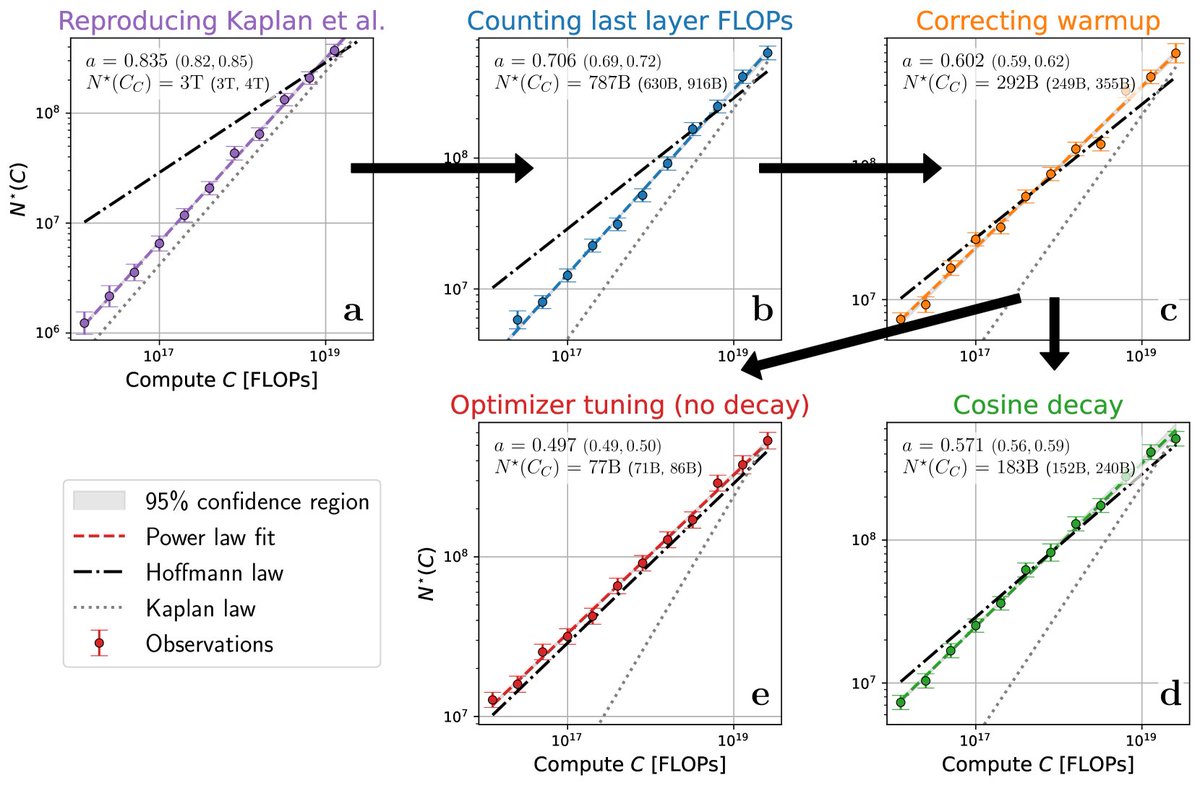
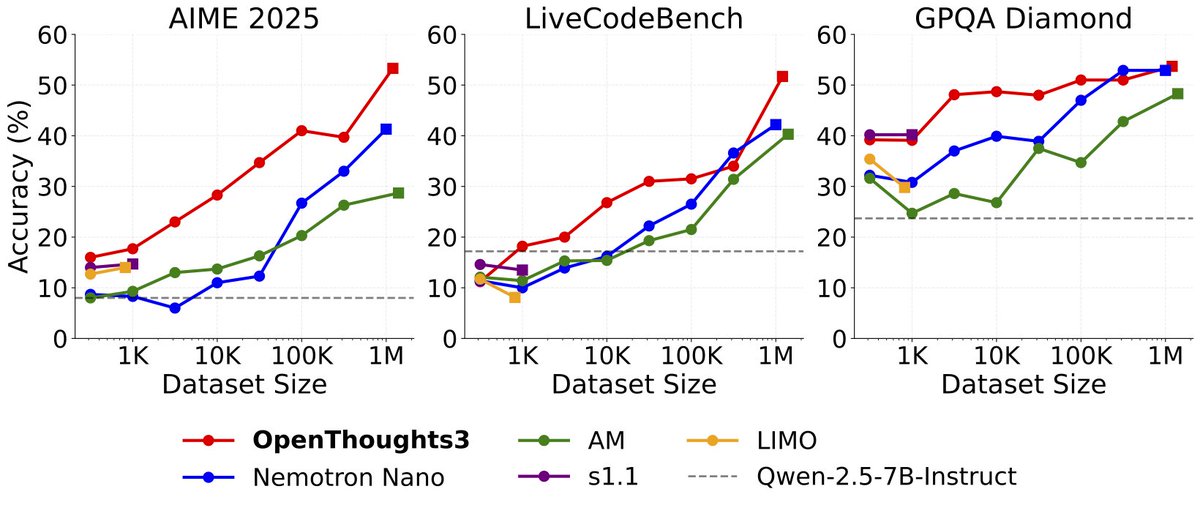
Very excited to finally release our paper for OpenThoughts!
After DataComp and DCLM, this is the third large open dataset my group has been building in collaboration with the DataComp community. This time, the focus is on post-training, specifically reasoning data.