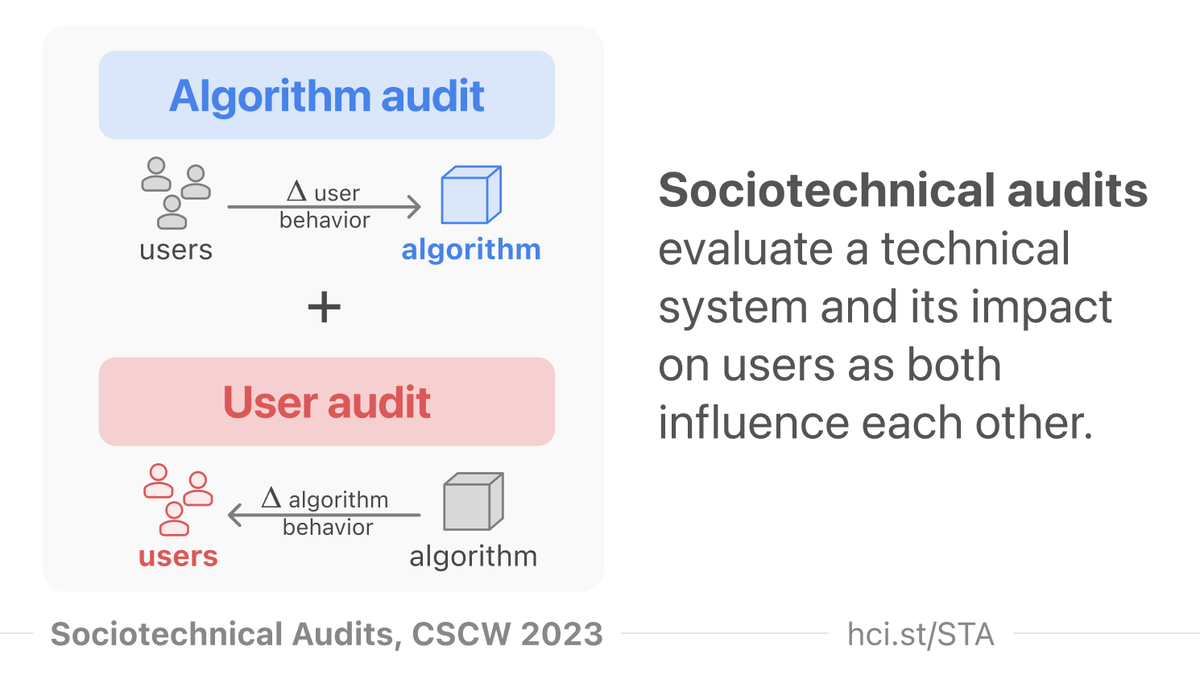
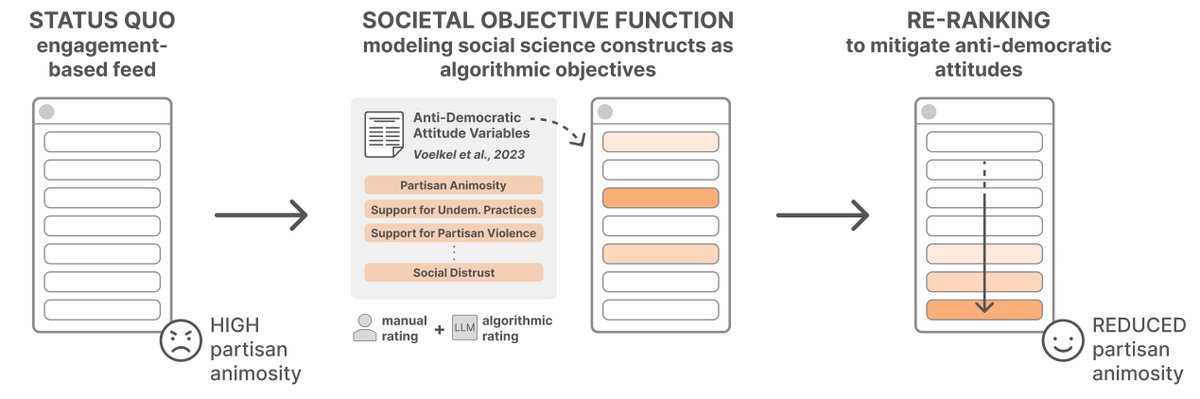
Pinned

Most of what I actually need help with, I never think to tell a model. But why is it on me to remember?
Our new paper asks: what if AI could proactively specialize to individuals and the tasks they’re carrying out at this very moment? 🧵

00:00