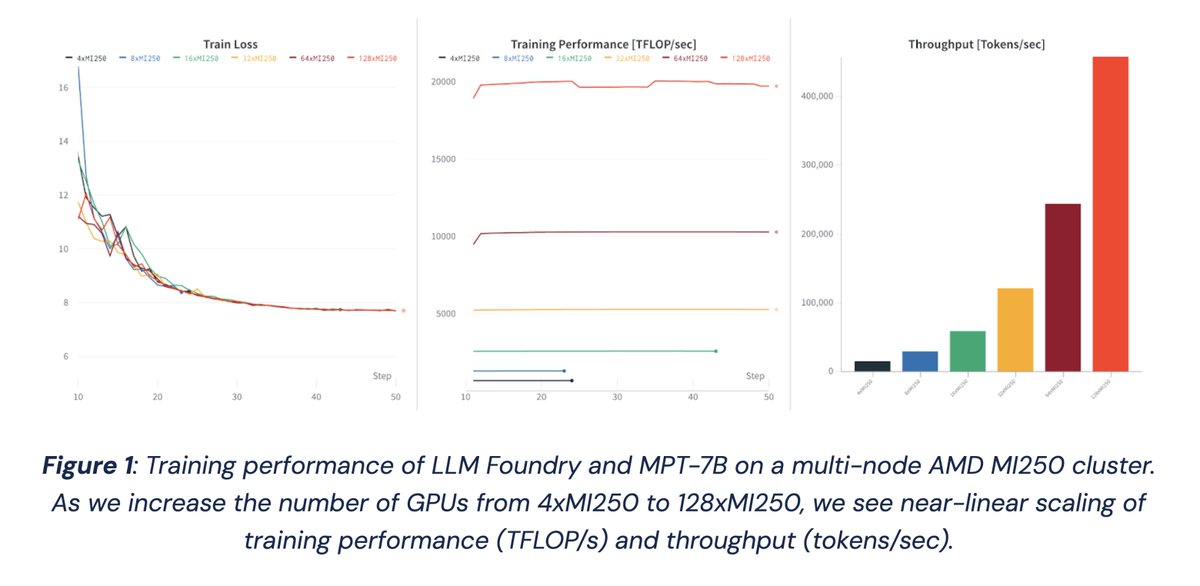
Ready for GPU independence weekend?
PyTorch 2.0 and LLM Foundry now work out of the box on ** AMD GPUs! ** We profiled MPT 1B-13B models on AMD MI250 and saw perf within 80% of A100-40GB, which could go up to 94% with better software.
It. Just. Works.