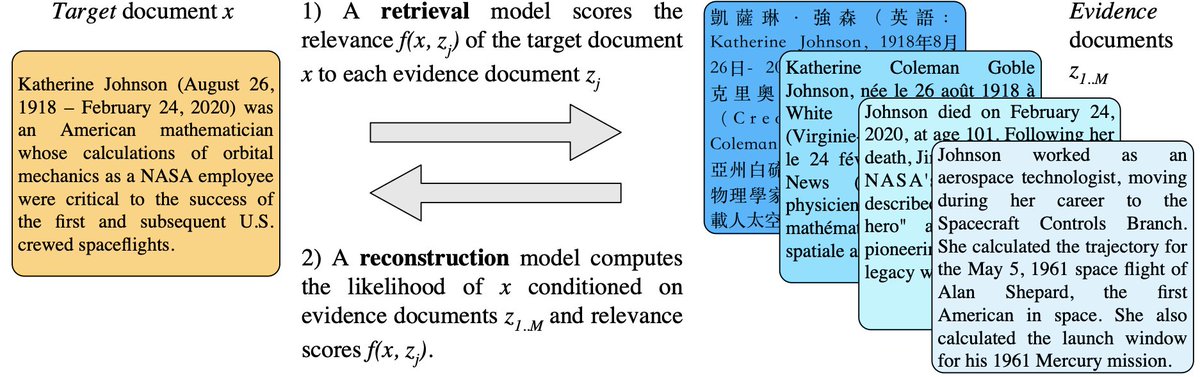
New paper in Science today on playing the classic negotiation game "Diplomacy" at a human level, by connecting language models with strategic reasoning! Our agent engages in intense and lengthy dialogues to persuade other players to follow its plans. This was really hard! 1/5