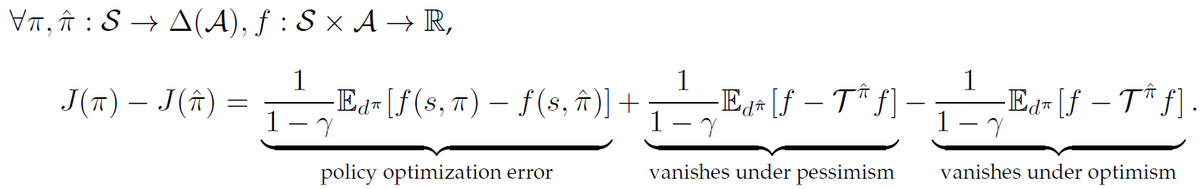

Pinned

Learning Q* with
+ poly-sized exploratory data
+ an arbitrary Q-class that contains Q*
...has seemed impossible for yrs, or so I believed when I talked at @RLtheory 2mo ago.
And what's the saying? Impossible is NOTHING
arxiv.org/abs/2008.04990
Exciting new work w/@tengyangx! 1/