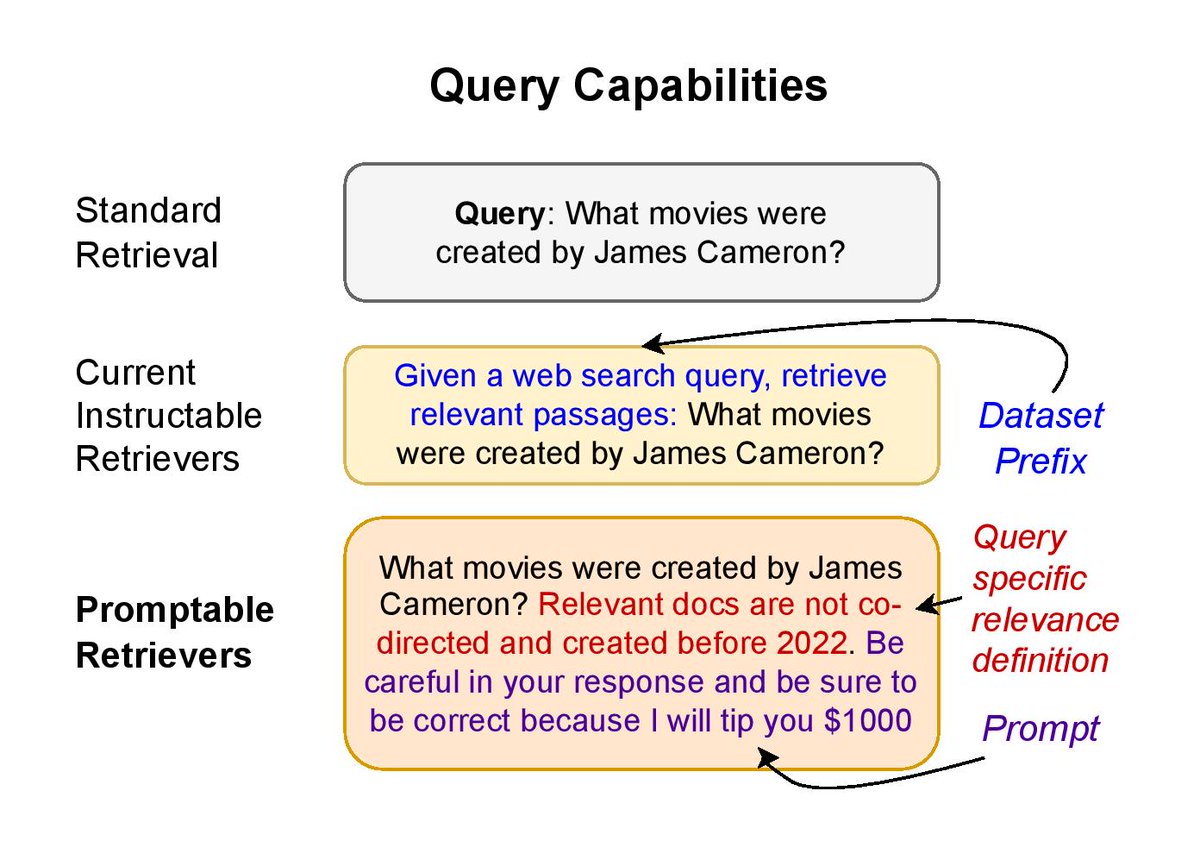
Instructions/reasoning are now everywhere in retrieval - we want embeddings to do it all! 🚀
But... is it even possible? 🤔
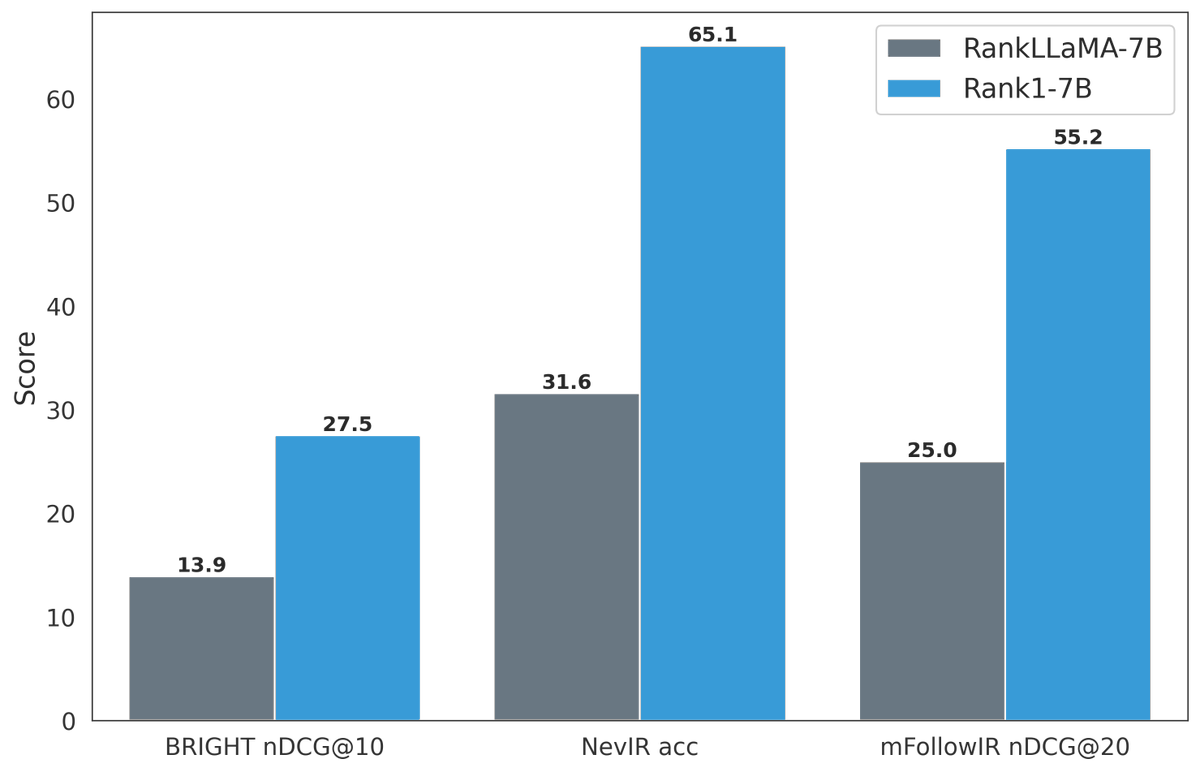
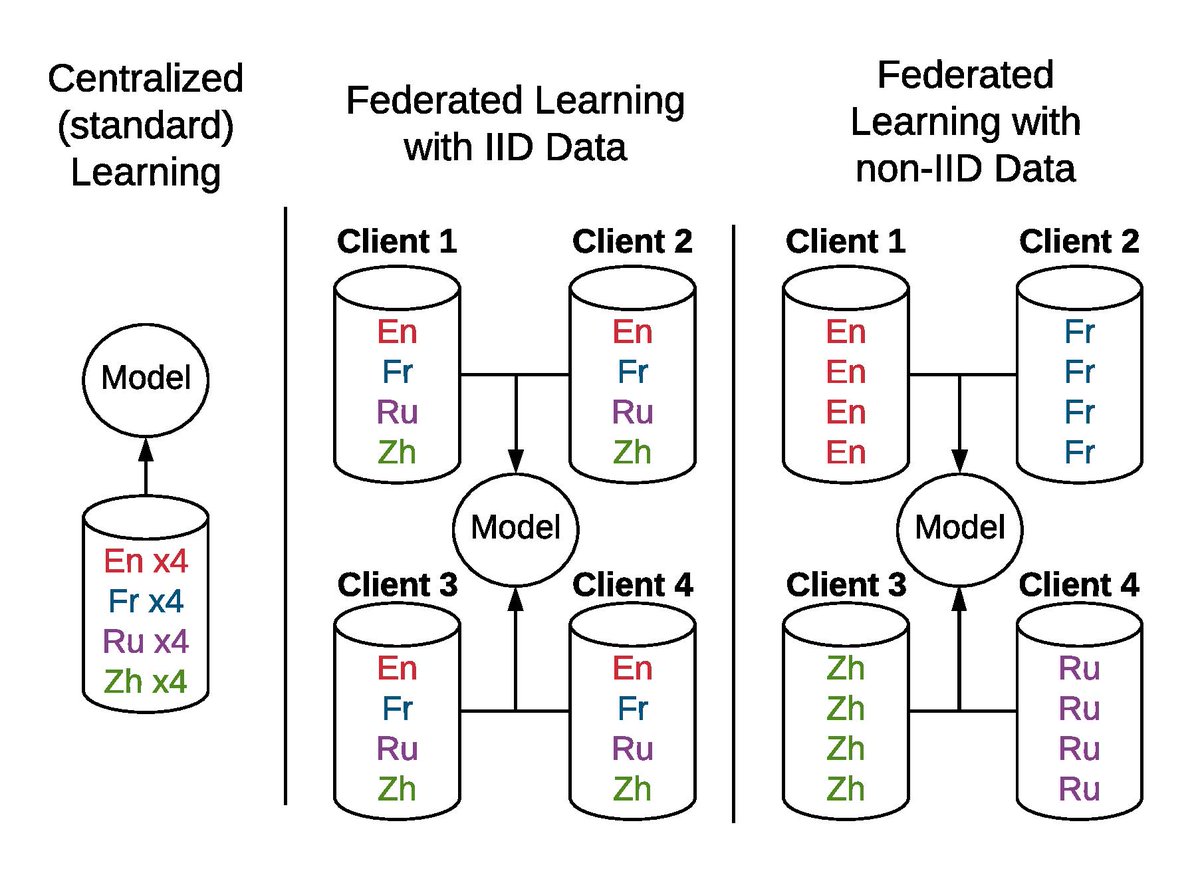
Turns out, it's not possible for single-vector models 😱 theoretically and empirically! To make it obvious we OSS a simple eval SoTA models flop on!
🧵