π0.7 handles diverse prompts that don't just say what to do, but also how to do it, including rich language and multimodal information, such as visual subgoal images. At test time, these images can be produced by a lightweight world model.
Compositional generalization is a key capability of large models like LLMs, but it has been elusive in robotics. Another emergent ability we found is to control a new robot (UR5e) to fold t-shirts, even though we didn't have any laundry folding data on this robot.
We are especially excited about how π0.7 seems to exhibit emergent compositional generalization: it can put together skills it learned in new ways based on the prompt, for example to figure out how to use an air fryer to cook a sweet potato.
Our newest model, π0.7, has some interesting emergent capabilities: it can control a new robot to fold shirts for which we had no shirt folding data, figure out how to use an appliance with language-based coaching, and perform a wide range of dexterous tasks all in one model!
π, But Make It Fly ✈️
We fine-tuned π0, a VLA model pretrained entirely on manipulators, to fly a drone that picks up objects, navigates through gates, and composes both skills from language commands.
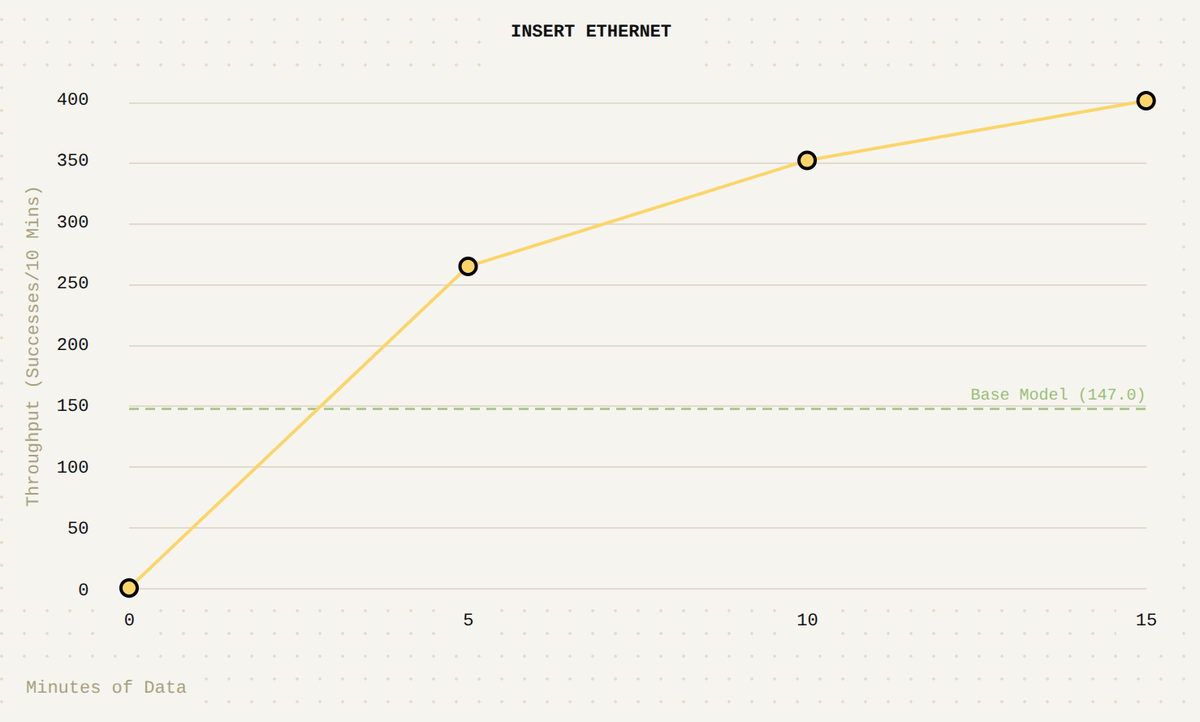
With RL, the robot can learn very precise tasks, like fastening a zip tie, and can actually do it more consistently and more quickly than even human teleoperation.
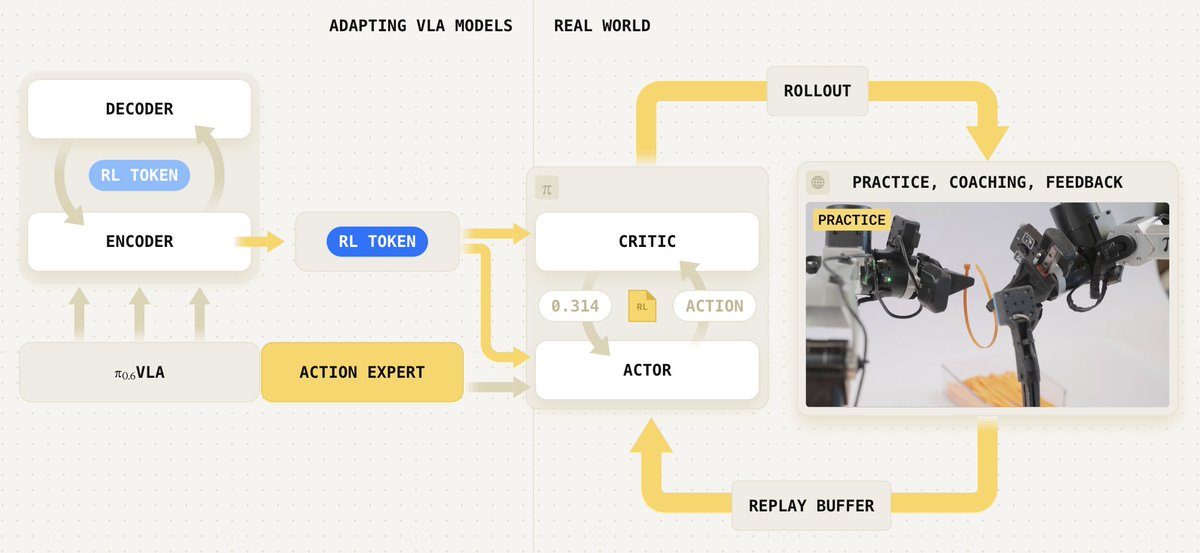
The key idea with RL tokens (RLT) is to compress our model’s (e.g., π-0.6) internal representations into a concise feature vector, which can be used by a very small actor and critic network that trains in real time even as the robot is practicing the task.