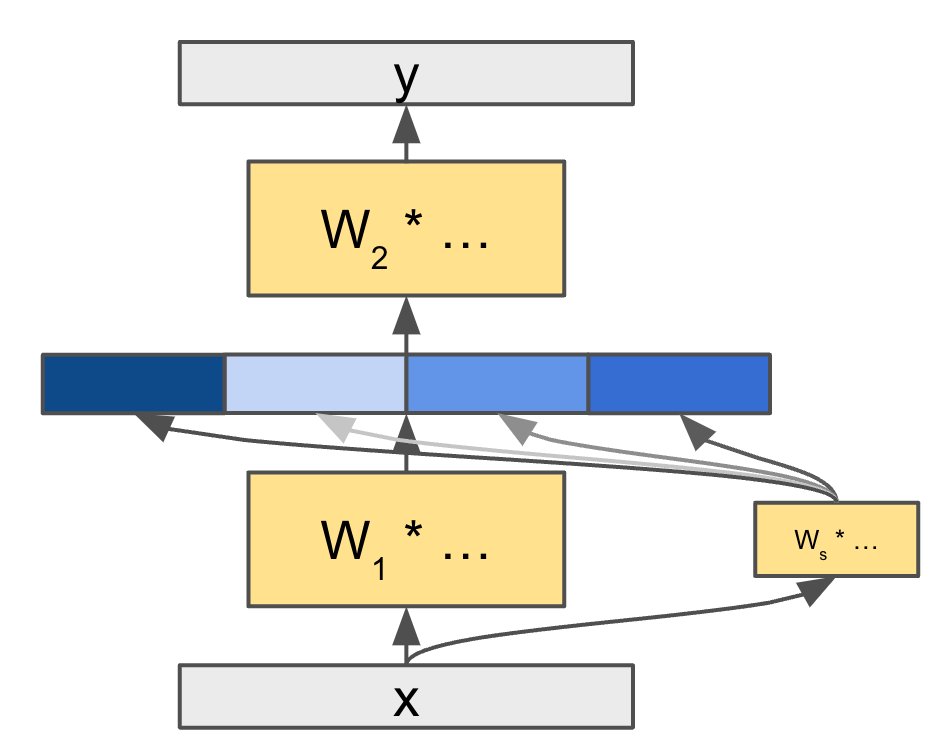
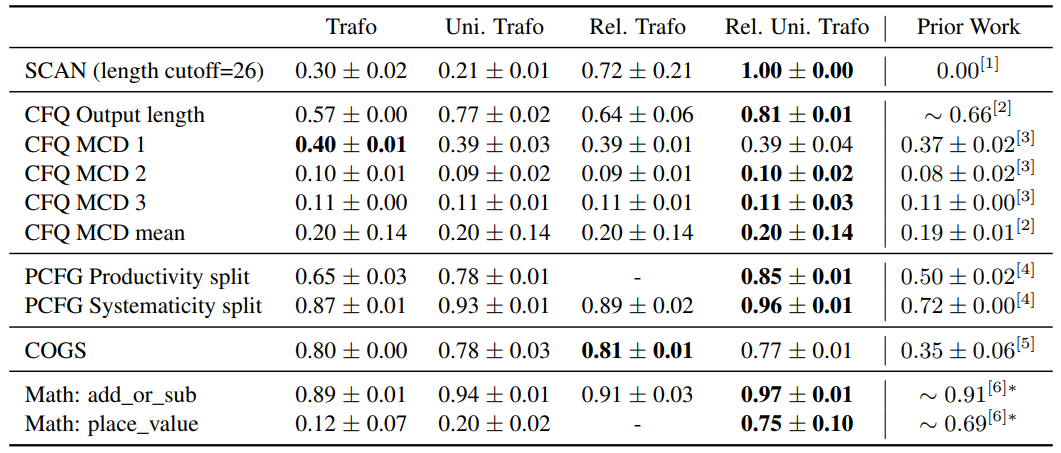
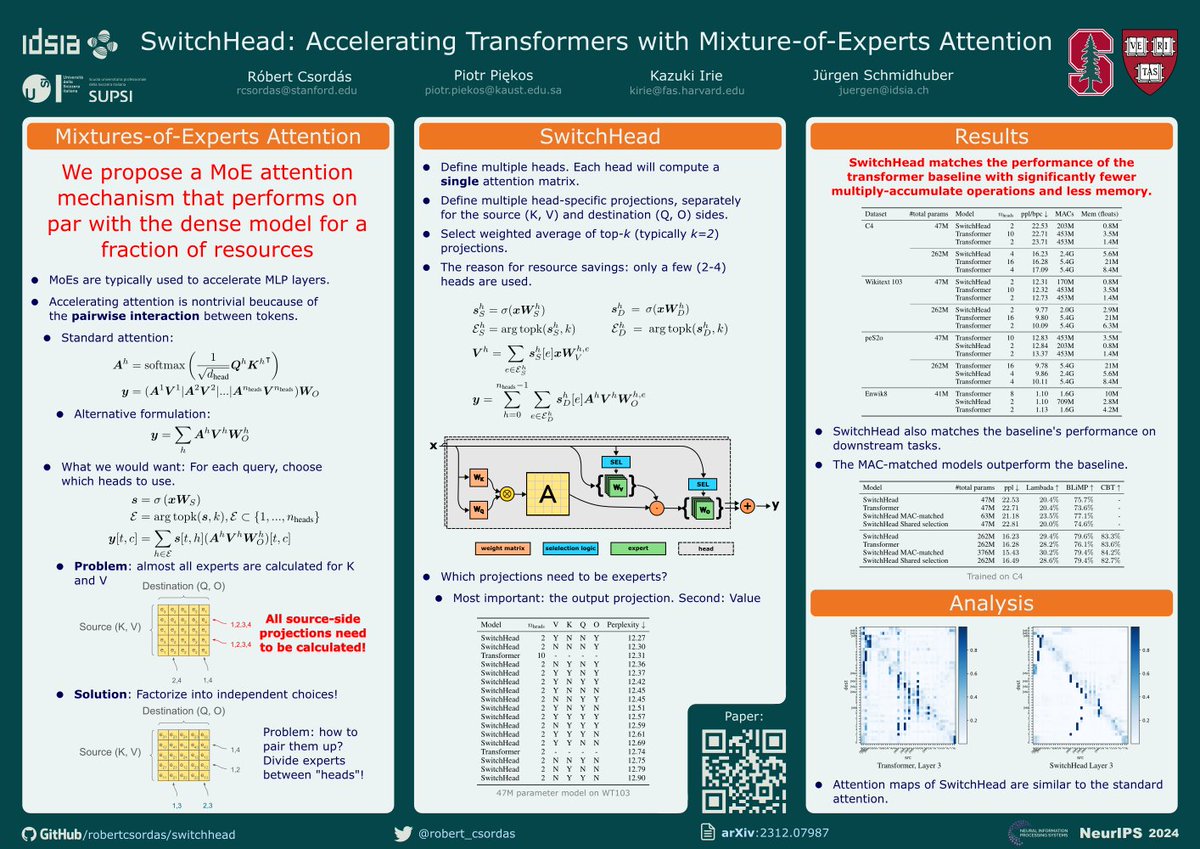
Your language model is wasting half of its layers to just refine probability distributions rather than doing interesting computations.
In our paper, we found that the second half of the layers of the Llama 3 models have minimal effect on future computations. 1/6