Pinned

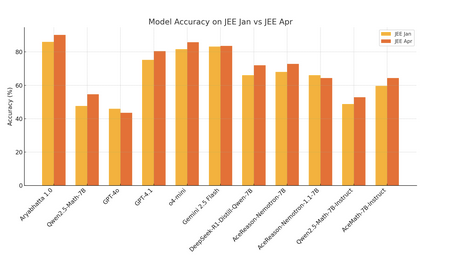
Excited to share Aryabhatta 1.0, our leading model that scores 90.2% on JEE Mains, outperforming frontier models like o4 mini and Gemini Flash 2.5
Trained by us at @AthenaAgentRL , in collaboration with @physics__wallah, using custom RLVR training on 130K+ curated JEE problems