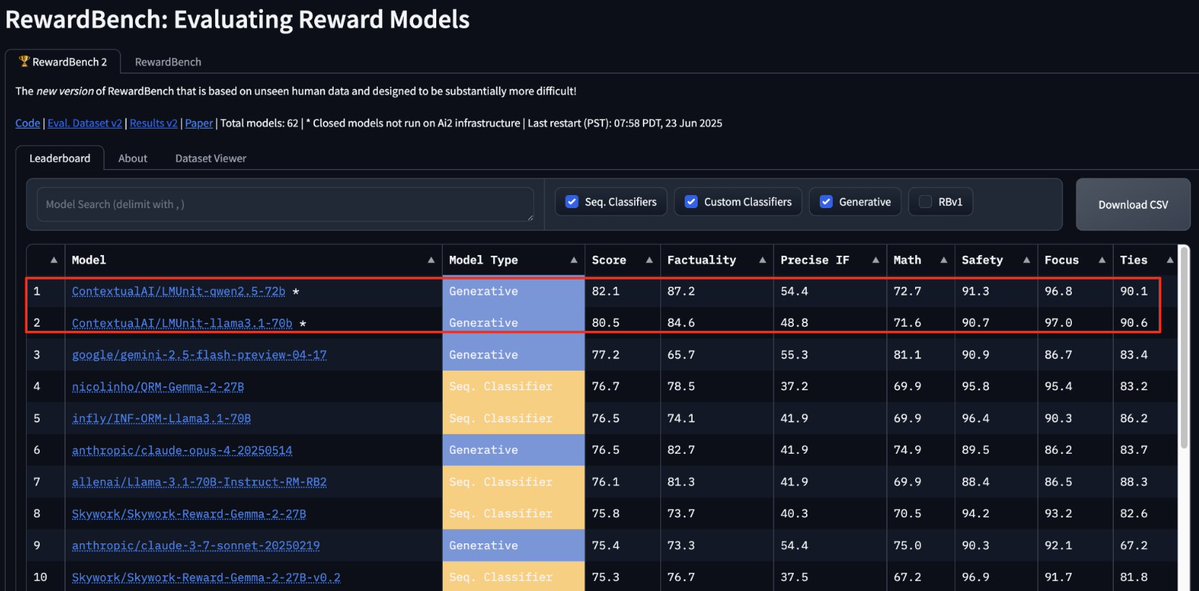
Tired of seeing O3 hallucinate? 😵💫
Today, I am excited to share how we built the least hallucinatory LLM in the 🌍
Our GLMv2, developed at @ContextualAI, just claimed 1st place 🥇 on the FACTS Grounded leaderboard by Google DeepMind — outperforming Gemini-2.5-pro, Claude 4, and

00:00