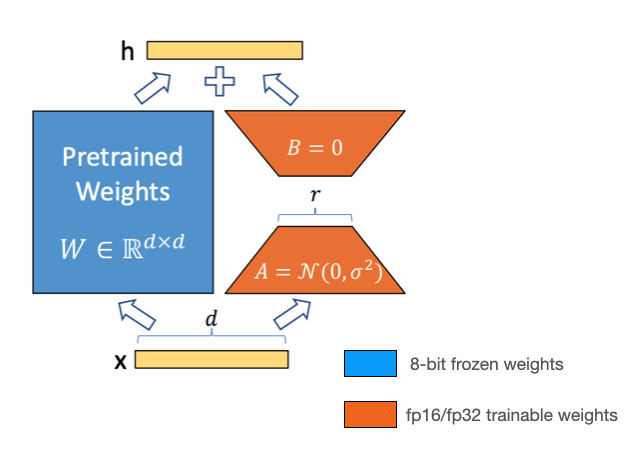
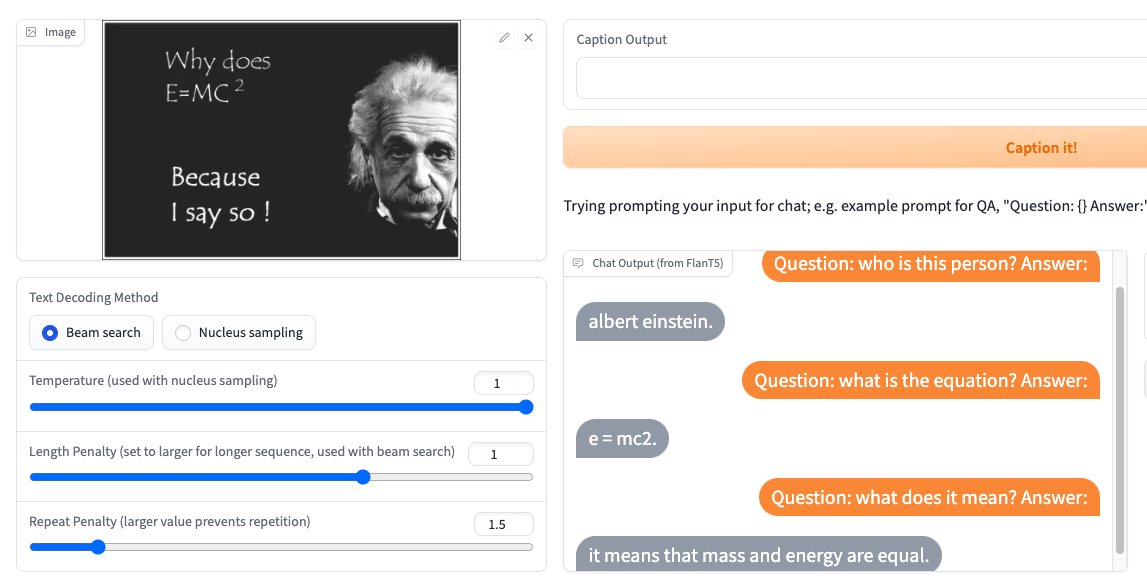
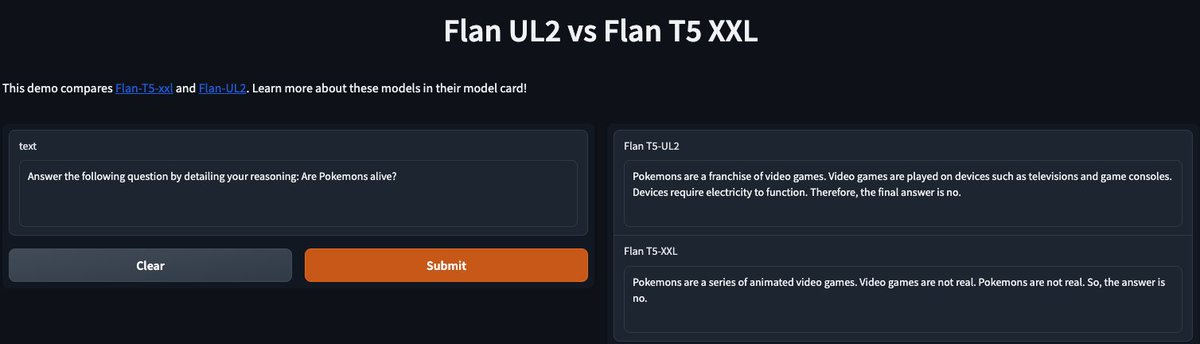
Llama-2 just got released by @Meta AI and you can already use it in the @huggingface ecosystem.
How to fine-tune the model on your own data? We release a simple fine-tuning script for single & multi-gpu to get you ready in few lines of code
gist.github.com/younesbelkada/…