https://blog.moreal.dev/2026/01/reproducible-commit/ 예전에 일할 때도 들었던 생각인데 요즘 이슈 적으면서 생각나서 적어봤습니다. (사실 여기 단문으로 써도 되는데 장황(?)해서..)

Lee Dogeon
@moreal@hackers.pub · 94 following · 84 followers
어느 한 개발자입니다.
 GitHub
GitHub- @moreal

@morealLee Dogeon 이렇게도 가능할 듯합니다:
mise use cargo:hongdown@0.2.0-dev.66+f2cdf12e![]() @hongminhee洪 民憙 (Hong Minhee) pre-release를 하고 계셨군요, 감사합니다!
@hongminhee洪 民憙 (Hong Minhee) pre-release를 하고 계셨군요, 감사합니다!
Zed에서 hongdown으로 포매팅하기
{
"languages": {
"Markdown": {
"formatter": {
"external": {
"command": "hongdown",
"arguments": ["-"]
}
}
}
}
}mise가 cargo backend도 지원하므로 아래 같이 릴리스 전에 미리 설치할 수 있다
# mise use cargo:https://github.com/dahlia/hongdown@rev:<sha>
mise use cargo:https://github.com/dahlia/hongdown@rev:c79718132e7fdfe667f602ce4123e3bb6a80e6b6@morealLee Dogeon 오… 이거 Hongdown 프로젝트 README.md에 추가해도 될까요?
![]() @hongminhee洪 民憙 (Hong Minhee) 아 물론이죠!! hongdown 잘 쓰겠습니다 🙏
@hongminhee洪 民憙 (Hong Minhee) 아 물론이죠!! hongdown 잘 쓰겠습니다 🙏
Zed에서 hongdown으로 포매팅하기
{
"languages": {
"Markdown": {
"formatter": {
"external": {
"command": "hongdown",
"arguments": ["-"]
}
}
}
}
}최근에 Manim-community 들어갔다가 GitHub에 있던 저장소가 Codeberg로 가게 된 걸 알게 되었는데 (지금은 또 GitHub에 돌아와있다) 그때 홈페이지에 How my GitHub Pages got Hacked 라는 글과 함께 해당 사실을 알리고 있었다[1]. 오늘 아마 이와 같은 내용으로 도메인을 뺏기는(?) 현상을 주변에서 봐서 verified domain들을 등록해놓았다.
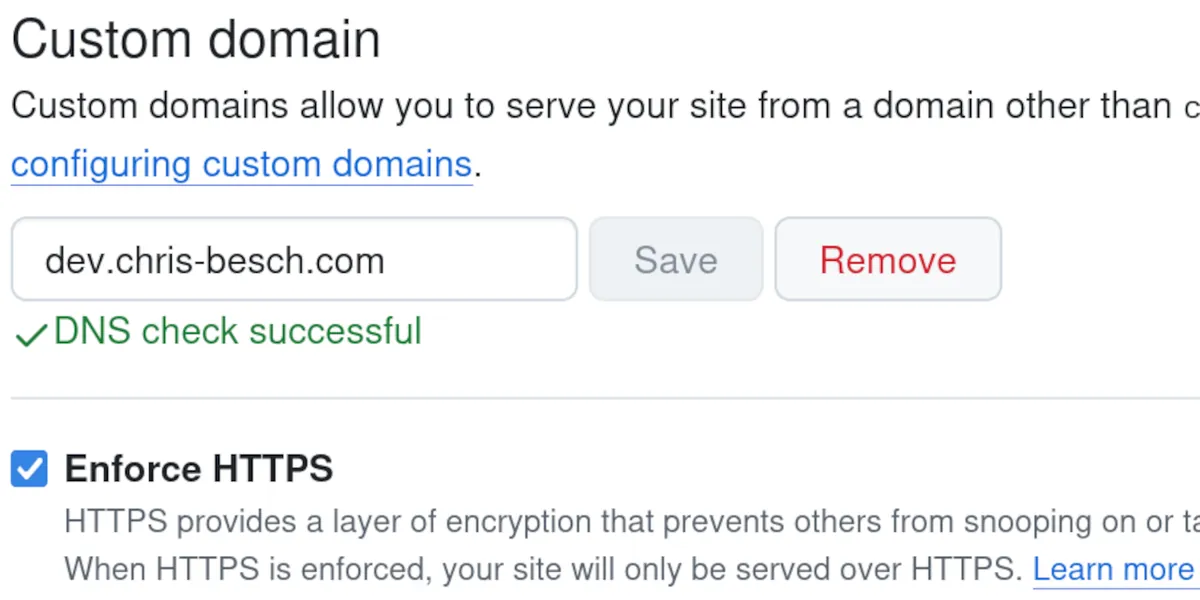

LLM에서 마크다운이 널리 쓰이게 되면서 안 보고 싶어도 볼 수 밖에 없게 된 흔한 꼬라지로 그림에서 보는 것처럼 마크다운 강조 표시(**)가 그대로 노출되어 버리는 광경이 있다. 이 문제는 CommonMark의 고질적인 문제로, 한 10년 전쯤에 보고한 적도 있는데 지금까지 어떤 해결책도 제시되지 않은 채로 방치되어 있다.
문제의 상세는 이러하다. CommonMark는 마크다운을 표준화하는 과정에서 파싱의 복잡도를 제한하기 위해 연속된 구분자(delimiter run)라는 개념을 넣었는데, 연속된 구분자는 어느 방향에 있느냐에 따라서 왼편(left-flanking)과 오른편(right-flanking)이라는 속성을 가질 수 있다(왼편이자 오른편일 수도 있고, 둘 다 아닐 수도 있다). 이 규칙에 따르면 **는 왼편의 연속된 구분자로부터 시작해서 오른편의 연속된 구분자로 끝나야만 한다. 여기서 중요한 건 왼편인지 오른편인지를 판단하는 데 외부 맥락이 전혀 안 들어가고 주변의 몇 글자만 보고 바로 결정된다는 것인데, 이를테면 왼편의 연속된 구분자는 **<보통 글자> 꼴이거나 <공백>**<기호> 또는 <기호>**<기호> 꼴이어야 한다. ("보통 글자"란 공백이나 기호가 아닌 글자를 가리킨다.) 첫번째 꼴은 아무래도 **마크다운**은 같이 낱말 안에 끼어 들어가 있는 연속된 구분자를 허용하기 위한 것이고, 두번째/세번째 꼴은 이 **"마크다운"** 형식은 같이 기호 앞에 붙어 있는 연속된 구분자를 제한적으로 허용하기 위한 것이라 해석할 수 있겠다. 오른편도 방향만 다르고 똑같은 규칙을 가지는데, 이 규칙으로 **마크다운(Markdown)**은을 해석해 보면 뒷쪽 **의 앞에는 기호가 들어 있으므로 뒤에는 공백이나 기호가 나와야 하지만 보통 글자가 나왔으므로 오른편이 아니라고 해석되어 강조의 끝으로 처리되지 않는 것이다.
CommonMark 명세에서도 설명되어 있지만, 이 규칙의 원 의도는 **이런 **식으로** 중첩되어** 강조된 문법을 허용하기 위한 것이다. 강조를 한답시고 **이런 ** 식으로 공백을 강조 문법 안쪽에 끼워 넣는 일이 일반적으로는 없으므로, 이런 상황에서 공백에 인접한 강조 문법은 항상 특정 방향에만 올 수 있다고 선언하는 것으로 모호함을 해소하는 것이다. 허나 CJK 환경에서는 공백이 아예 없거나 공백이 있어도 한국어처럼 낱말 안에서 기호를 쓰는 경우가 드물지 않기 때문에, 이런 식으로 어느 연속된 구분자가 왼편인지 오른편인지 추론하는 데 한계가 있다는 것이다. 단순히 <보통 문자>**<기호>도 왼편으로 해석하는 식으로 해서 **마크다운(Markdown)**은 같은 걸 허용한다 하더라도, このような**[状況](...)**は 이런 상황은 어쩔 것인가? 내가 느끼기에는 중첩되어 강조된 문법의 효용은 제한적인 반면 이로 인해 생기는 CJK 환경에서의 불편함은 명확하다. 그리고 LLM은 CommonMark의 설계 의도 따위는 고려하지 않고 실제 사람들이 사용할 법한 식으로 마크다운을 쓰기 때문에, 사람들이 막연하게 가지고만 있던 이런 불편함이 그대로 표면화되어 버린 것이고 말이다.
![* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [강조 처리된 "비숍(Ba5)" 앞뒤에 마크다운의 강조 표시 "**"가 그대로 노출되어 있다.]](/Using-https-media.hackers.pub/note-media/17646c5d-3f9d-472b-9d56-dd34006ad291.webp)
프로그래밍 언어 문법을 만들때, 비교 연산자에 <, <=, >, >= 등이 있는데, 어차피 좌우 순서만 바꾸면 되니까, >, >= 같은걸 그냥 압수하고 <, <=만 쓰게 한다음에 >, >= 요건 다른 용도로 쓰면 어떨까하는 생각이 듬.
Lee Dogeon shared the below article:
Designing type-safe sync/async mode support in TypeScript
洪 民憙 (Hong Minhee) @hongminhee@hackers.pub
I recently added sync/async mode support to Optique, a type-safe CLI parser
for TypeScript. It turned out to be one of the trickier features I've
implemented—the object() combinator alone needed to compute a combined mode
from all its child parsers, and TypeScript's inference kept hitting edge cases.
What is Optique?
Optique is a type-safe, combinatorial CLI parser for TypeScript, inspired by Haskell's optparse-applicative. Instead of decorators or builder patterns, you compose small parsers into larger ones using combinators, and TypeScript infers the result types.
Here's a quick taste:
import { object } from "@optique/core/constructs";
import { argument, option } from "@optique/core/primitives";
import { string, integer } from "@optique/core/valueparser";
import { run } from "@optique/run";
const cli = object({
name: argument(string()),
count: option("-n", "--count", integer()),
});
// TypeScript infers: { name: string; count: number | undefined }
const result = run(cli); // sync by defaultThe type inference works through arbitrarily deep compositions—in most cases, you don't need explicit type annotations.
How it started
Lucas Garron (@lgarron) opened an issue requesting
async support for shell completions. He wanted to provide
Tab-completion suggestions by running shell commands like
git for-each-ref to list branches and tags.
// Lucas's example: fetching Git branches and tags in parallel
const [branches, tags] = await Promise.all([
$`git for-each-ref --format='%(refname:short)' refs/heads/`.text(),
$`git for-each-ref --format='%(refname:short)' refs/tags/`.text(),
]);At first, I didn't like the idea. Optique's entire API was synchronous, which made it simpler to reason about and avoided the “async infection” problem where one async function forces everything upstream to become async. I argued that shell completion should be near-instantaneous, and if you need async data, you should cache it at startup.
But Lucas pushed back. The filesystem is a database, and many useful completions inherently require async work—Git refs change constantly, and pre-caching everything at startup doesn't scale for large repos. Fair point.
What I needed to solve
So, how do you support both sync and async execution modes in a composable parser library while maintaining type safety?
The key requirements were:
parse()returnsTorPromise<T>complete()returnsTorPromise<T>suggest()returnsIterable<T>orAsyncIterable<T>- When combining parsers, if any parser is async, the combined result must be async
- Existing sync code should continue to work unchanged
The fourth requirement is the tricky one. Consider this:
const syncParser = flag("--verbose");
const asyncParser = option("--branch", asyncValueParser);
// What's the type of this?
const combined = object({ verbose: syncParser, branch: asyncParser });The combined parser should be async because one of its fields is async. This means we need type-level logic to compute the combined mode.
Five design options
I explored five different approaches, each with its own trade-offs.
Option A: conditional types with mode parameter
Add a mode type parameter to Parser and use conditional types:
type Mode = "sync" | "async";
type ModeValue<M extends Mode, T> = M extends "async" ? Promise<T> : T;
interface Parser<M extends Mode, TValue, TState> {
parse(context: ParserContext<TState>): ModeValue<M, ParserResult<TState>>;
// ...
}The challenge is computing combined modes:
type CombineModes<T extends Record<string, Parser<any, any, any>>> =
T[keyof T] extends Parser<infer M, any, any>
? M extends "async" ? "async" : "sync"
: never;Option B: mode parameter with default value
A variant of Option A, but place the mode parameter first with a default
of "sync":
interface Parser<M extends Mode = "sync", TValue, TState> {
readonly $mode: M;
// ...
}The default value maintains backward compatibility—existing user code keeps working without changes.
Option C: separate interfaces
Define completely separate Parser and AsyncParser interfaces with
explicit conversion:
interface Parser<TValue, TState> { /* sync methods */ }
interface AsyncParser<TValue, TState> { /* async methods */ }
function toAsync<T, S>(parser: Parser<T, S>): AsyncParser<T, S>;Simpler to understand, but requires code duplication and explicit conversions.
Option D: union return types for suggest() only
The minimal approach. Only allow suggest() to be async:
interface Parser<TValue, TState> {
parse(context: ParserContext<TState>): ParserResult<TState>; // always sync
suggest(context: ParserContext<TState>, prefix: string):
Iterable<Suggestion> | AsyncIterable<Suggestion>; // can be either
}This addresses the original use case but doesn't help if async parse() is
ever needed.
Option E: fp-ts style HKT simulation
Use the technique from fp-ts to simulate Higher-Kinded Types:
interface URItoKind<A> {
Identity: A;
Promise: Promise<A>;
}
type Kind<F extends keyof URItoKind<any>, A> = URItoKind<A>[F];
interface Parser<F extends keyof URItoKind<any>, TValue, TState> {
parse(context: ParserContext<TState>): Kind<F, ParserResult<TState>>;
}The most flexible approach, but with a steep learning curve.
Testing the idea
Rather than commit to an approach based on theoretical analysis, I created a prototype to test how well TypeScript handles the type inference in practice. I published my findings in the GitHub issue:
Both approaches correctly handle the “any async → all async” rule at the type level. (…) Complex conditional types like
ModeValue<CombineParserModes<T>, ParserResult<TState>>sometimes require explicit type casting in the implementation. This only affects library internals. The user-facing API remains clean.
The prototype validated that Option B (explicit mode parameter with default) would work. I chose it for these reasons:
- Backward compatible: The default
"sync"keeps existing code working - Explicit: The mode is visible in both types and runtime (via a
$modeproperty) - Debuggable: Easy to inspect the current mode at runtime
- Better IDE support: Type information is more predictable
How CombineModes works
The CombineModes type computes whether a combined parser should be sync or
async:
type CombineModes<T extends readonly Mode[]> = "async" extends T[number]
? "async"
: "sync";This type checks if "async" is present anywhere in the tuple of modes.
If so, the result is "async"; otherwise, it's "sync".
For combinators like object(), I needed to extract modes from parser
objects and combine them:
// Extract the mode from a single parser
type ParserMode<T> = T extends Parser<infer M, unknown, unknown> ? M : never;
// Combine modes from all values in a record of parsers
type CombineObjectModes<T extends Record<string, Parser<Mode, unknown, unknown>>> =
CombineModes<{ [K in keyof T]: ParserMode<T[K]> }[keyof T][]>;Runtime implementation
The type system handles compile-time safety, but the implementation also needs
runtime logic. Each parser has a $mode property that indicates its execution
mode:
const syncParser = option("-n", "--name", string());
console.log(syncParser.$mode); // "sync"
const asyncParser = option("-b", "--branch", asyncValueParser);
console.log(asyncParser.$mode); // "async"Combinators compute their mode at construction time:
function object<T extends Record<string, Parser<Mode, unknown, unknown>>>(
parsers: T
): Parser<CombineObjectModes<T>, ObjectValue<T>, ObjectState<T>> {
const parserKeys = Reflect.ownKeys(parsers);
const combinedMode: Mode = parserKeys.some(
(k) => parsers[k as keyof T].$mode === "async"
) ? "async" : "sync";
// ... implementation
}Refining the API
Lucas suggested an important refinement during our
discussion. Instead of having run() automatically choose between sync and
async based on the parser mode, he proposed separate functions:
Perhaps
run(…)could be automatic, andrunSync(…)andrunAsync(…)could enforce that the inferred type matches what is expected.
So we ended up with:
run(): automatic based on parser moderunSync(): enforces sync mode at compile timerunAsync(): enforces async mode at compile time
// Automatic: returns T for sync parsers, Promise<T> for async
const result1 = run(syncParser); // string
const result2 = run(asyncParser); // Promise<string>
// Explicit: compile-time enforcement
const result3 = runSync(syncParser); // string
const result4 = runAsync(asyncParser); // Promise<string>
// Compile error: can't use runSync with async parser
const result5 = runSync(asyncParser); // Type error!I applied the same pattern to parse()/parseSync()/parseAsync() and
suggest()/suggestSync()/suggestAsync() in the facade functions.
Creating async value parsers
With the new API, creating an async value parser for Git branches looks like this:
import type { Suggestion } from "@optique/core/parser";
import type { ValueParser, ValueParserResult } from "@optique/core/valueparser";
function gitRef(): ValueParser<"async", string> {
return {
$mode: "async",
metavar: "REF",
parse(input: string): Promise<ValueParserResult<string>> {
return Promise.resolve({ success: true, value: input });
},
format(value: string): string {
return value;
},
async *suggest(prefix: string): AsyncIterable<Suggestion> {
const { $ } = await import("bun");
const [branches, tags] = await Promise.all([
$`git for-each-ref --format='%(refname:short)' refs/heads/`.text(),
$`git for-each-ref --format='%(refname:short)' refs/tags/`.text(),
]);
for (const ref of [...branches.split("\n"), ...tags.split("\n")]) {
const trimmed = ref.trim();
if (trimmed && trimmed.startsWith(prefix)) {
yield { kind: "literal", text: trimmed };
}
}
},
};
}Notice that parse() returns Promise.resolve() even though it's synchronous.
This is because the ValueParser<"async", T> type requires all methods to use
async signatures. Lucas pointed out this is a minor ergonomic issue. If only
suggest() needs to be async, you still have to wrap parse() in a Promise.
I considered per-method mode granularity (e.g., ValueParser<ParseMode, SuggestMode, T>), but the implementation complexity would multiply
substantially. For now, the workaround is simple enough:
// Option 1: Use Promise.resolve()
parse(input) {
return Promise.resolve({ success: true, value: input });
}
// Option 2: Mark as async and suppress the linter
// biome-ignore lint/suspicious/useAwait: sync implementation in async ValueParser
async parse(input) {
return { success: true, value: input };
}What it cost
Supporting dual modes added significant complexity to Optique's internals. Every combinator needed updates:
- Type signatures grew more complex with mode parameters
- Mode propagation logic had to be added to every combinator
- Dual implementations were needed for sync and async code paths
- Type casts were sometimes necessary in the implementation to satisfy TypeScript
For example, the object() combinator went from around 100 lines to around
250 lines. The internal implementation uses conditional logic based on the
combined mode:
if (combinedMode === "async") {
return {
$mode: "async" as M,
// ... async implementation with Promise chains
async parse(context) {
// ... await each field's parse result
},
};
} else {
return {
$mode: "sync" as M,
// ... sync implementation
parse(context) {
// ... directly call each field's parse
},
};
}This duplication is the cost of supporting both modes without runtime overhead for sync-only use cases.
Lessons learned
Listen to users, but validate with prototypes
My initial instinct was to resist async support. Lucas's persistence and concrete examples changed my mind, but I validated the approach with a prototype before committing. The prototype revealed practical issues (like TypeScript inference limits) that pure design analysis would have missed.
Backward compatibility is worth the complexity
Making "sync" the default mode meant existing code continued to work
unchanged. This was a deliberate choice. Breaking changes should require
user action, not break silently.
Unified mode vs per-method granularity
I chose unified mode (all methods share the same sync/async mode) over
per-method granularity. This means users occasionally write
Promise.resolve() for methods that don't actually need async, but the
alternative was multiplicative complexity in the type system.
Designing in public
The entire design process happened in a public GitHub issue. Lucas, Giuseppe,
and others contributed ideas that shaped the final API. The
runSync()/runAsync() distinction came directly from Lucas's feedback.
Conclusion
This was one of the more challenging features I've implemented in Optique. TypeScript's type system is powerful enough to encode the “any async means all async” rule at compile time, but getting there required careful design work and prototyping.
What made it work: conditional types like ModeValue<M, T> can bridge the gap
between sync and async worlds. You pay for it with implementation complexity,
but the user-facing API stays clean and type-safe.
Optique 0.9.0 with async support is currently in pre-release testing. If you'd like to try it, check out PR #70 or install the pre-release:
npm add @optique/core@0.9.0-dev.212 @optique/run@0.9.0-dev.212
deno add --jsr @optique/core@0.9.0-dev.212 @optique/run@0.9.0-dev.212Feedback is welcome!
Lee Dogeon shared the below article:
`X-Frame-Options` 의 악몽에서 깨어나세요, 프록시 서버 개발기
소피아 @async3619@hackers.pub
X-Frame-Options 의 악몽에서 깨어나세요, 프록시 서버 개발기
X-Frame-Options? 그게 뭔가요?
우리가 아는 몇몇 대형 웹 서비스들(유튜브 등)은 보통의 경우 다른 웹 사이트에서 iframe 요소를 통해 임베딩 되는 것을 거부하지 않습니다. 다만, 몇몇 웹 서비스는 다른 웹 페이지에서 iframe 요소를 통해 표시되길 거부합니다. 제품 정책 및 보안상의 이유로 표시를 거부하는 목적이 있겠습니다.
이러한 니즈를 충족시킬 수 있는 HTTP 헤더가 X-Frame-Options 입니다. 이 헤더의 값을 SAMEORIGIN 내지는 DENY로 설정하면, 직관적인 값에 따라 알맞게 프레임 내 임베딩 가능 여부를 결정할 수 있습니다.

위 이미지에서 볼 수 있듯, 네이버는 X-Frame-Options 헤더를 명시함으로써 그 어떠한 출처에서도 프레임 내에 임베딩 되는 것을 거부한 상황입니다. #
왜 이걸 우회하나요?

웹 페이지 내에 다른 웹 페이지가 임베딩 되어 '미리보기' 처럼 제공되는 경험을 보신 적이 있으신가요? Omakase AI는 자사 프로덕트의 데모를 위와 같이 제공하고 있습니다. 캡쳐하여 실시간으로 전송되는 영상의 화면 위에, 자사 컨텐츠를 올려두어 실제 적용 시에 어떤 네러티브를 제공할지 데모 형식으로 보여줍니다.
문제는 이 모든 경험이 영상을 통해 진행 된다는 점 입니다. 영상 전송은 필연적으로 지연 시간이 존재할 수 밖에 없습니다. 여러분이 스크롤을 내리고, 클릭을 하는 등의 작은 인터렉션 하나가, 큰 지연 시간 뒤에 처리가 된다고 하면 유저는 답답하고 매끄럽지 않음을 느낄 것이고 이는 곧 이탈로 이어질 가능성이 있습니다. (구글은 비슷한 맥락에서 Core Web Vitals로써 INP를 설명하고 있습니다)
따라서 저는 영상을 보내는 나이브한 방법 이외의 유저의 브라우저에서 외부 웹 서비스를 표시할 좋은 방법을 찾아야 했고, 그것이 바로 프레임 내지는 iframe을 사용하는 방법 이었습니다. 이런 맥락에서 X-Frame-Options를 우회할 필요가 생긴 것 입니다.
어떻게 했나요?
중간자의 필요성

우리는 정상적인 방법으로는 제 3자 출처의 요청을 가로채어 응답 데이터 및 헤더를 조작할 수 없음을 잘 알고 있습니다. 여기서 필요한게 중간자 (Man in the Middle) 입니다. 누군가를 클라이언트 - 원격지 서버 사이에 두어, 서로에게 오가는 요청과 응답을 수정하는 작업을 수행하도록 하는 것 입니다. 그렇게 하면, 둘은 각자 수신한 요청과 응답이 모두 원본인지, 수정한 것인지 알 수 있는 방법은 거의 없을 것 입니다.[1]

이 중간자 역할을 하는 프록시 서버를 중간에 두어 요청을 모두 프록시 서버를 거치도록 하는 방법을 이용하는 것 입니다. 간단하게는 X-Frame-Options 응답 헤더의 제거가 있을 것 입니다. 중간자가 X-Frame-Options 헤더를 제거함으로 응답을 수신하는 클라이언트 브라우저의 iframe 요소는 큰 문제 없이 내용을 표시할 수 있게 됩니다.
여기서 끝이 아니다. URL을 조작하기
처음에는 그저 GET Query Parameter로 프록시 서버에게 어떤 원격 URL을 프록시 할 것인지 명시하도록 구현 했습니다. 예를 들면 다음과 같은 형식이 될 수 있겠습니다:
https://example.com/proxy?target=https://www.naver.com/...보통의 경우에는 별 문제 없이 동작 했습니다만, 재앙은 그다지 먼 곳에 있지 않았습니다. 만약 다음과 같은 코드가 원격지 웹 서비스 코드에 있다고 해봅시다. 아래 코드는 무신사 웹 페이지의 빌드된 소스코드 입니다:
import {E as k0} from "./vendor/react-error-boundary.js";
import {b as o0, d as Wt} from "./vendor/react-router.js";
import {d as F0} from "./vendor/dayjs.js";
import {L as Qt} from "./vendor/lottie.js";
import "./vendor/scheduler.js";
import "./vendor/prop-types.js";
import "./vendor/react-fast-compare.js";
import "./vendor/invariant.js";
import "./vendor/shallowequal.js";
import "./vendor/@remix-run.js";
import "./vendor/tslib.js";
import "./vendor/@emotion.js";
import "./vendor/stylis.js";
import "./vendor/framer-motion.js";
import "./vendor/motion-utils.js";
import "./vendor/motion-dom.js";무신사는 내부적으로 ESM을 사용해서, import 구문을 통해 필요한 에셋을 불러오는 코드를 사용중에 있습니다. 문제는 여기서 발생합니다. import 의 대상이 되는 소스코드가 상대 경로를 따르게 되어 아래와 같은 결과를 초래하게 됩니다.
https://example.com/proxy?target=https://www.naver.com/...
위와 같은 URL을 표시하고 있는 `iframe` 요소에서,
`import "./vendor/framer-motion.js"` 구문을 만난다면..
https://example.com/proxy/vendor/framer-motion.js 를 요청하게 됨.이를 해결하기 위해, 프록시 된 대상 URL에 대한 개념의 도입이 필요 했습니다. 상대 경로 진입에도 안정적으로 작동할 수 있는 새로운 방식의 접근이 필요 했습니다. 저는
- 상대 경로 접근에도 안전하며,
- 원본 URL의 구조를 그대로 남길 수 있는 구조
를 생각해 냈어야 했고, 그 결과는 이렇습니다. https://section.blog.naver.com/BlogHome.naver?directoryNo=0¤tPage=1&groupId=0 를 예시로 들면, 프록시화 (Proxified) 된 URL은 다음과 같은 것 입니다.
https://example.com/proxy/section/blog/naver/com/_/BlogHome.naver?...URL hostname의 . 구분자를 /로 치환하고, 이후의 모든 pathname, search 등은 모두 _ 구분자 뒤로 넘김으로서 URL의 원형을 유지할 수 있게 됩니다. 추가적으로 상대 경로 접근에도 안전한 URL을 만들 수 있습니다.
최종 보스가 남아있다. HTML API 후킹하기
우리는 상대 경로 문제를 해결하기 위해 URL을 프록시화 하는 방법을 사용했고, 이는 제대로 동작하는 듯 해보였습니다. 악몽은 React, Vue 등의 SPA 웹 앱을 프록시하여 표시하는 데에서 시작 되었습니다.
React, Vue 와 같은 프레임워크들은 History API 및 window.location 객체를 기반으로 한 Routing 기능을 제공하고 있습니다.[2] 이 말은, 결국엔 어떤 프레임워크가 되었든 저수준 빌트인 자바스크립트 API를 사용할 수 밖에 없다는 것을 의미 합니다. 그렇다면 직관적으로 생각 해봤을 때,
window(및globalThis) 객체의location속성의 값을 변경해주면 되지 않겠나?
라고 생각할 수 있습니다. 그러나 이는 불가능 합니다.

어떠한 이유 때문인지는 알 길이 없었지만, 자바스크립트는 그렇게 만만한 존재가 아니었습니다. 다른 좋은 방법을 찾아야 할 필요가 있었고, 결론에 도달하는 데에는 오랜 시간이 걸리지 않았습니다. 그것은 바로 원격지 웹 페이지에서 실행되는 모든 스크립트의 window.location 객체 접근을 감시하면 어떨지에 대한 아이디어 였습니다.
번들된 소스코드의 경우 대체적으로 다음과 같은 형식을 가지게 됩니다:
const l = window.location;
/* ... */ l.pathname /* ... */여기서 우리는 변수 l이 window.location의 별칭인지 소스코드만 분석해서는 알기 매우 어렵습니다. 따라서, babel을 사용해서 소스코드를 AST로 분석하고, 모든 프로퍼티 접근을 특정 함수 호출로 변환하면, '특정 함수'에서 모든 것을 처리할 수 있으니 좋을 것 같다는 생각이 있었고, 실행에 옮겼습니다:
const l = window.location;
l.pathname;
// 위 코드는 아래와 같이 변환됨
const l = __internal_get__(window, 'location');
__internal_get__(l, 'pathname');__internal_get__ 함수 내부에서 첫번째 인자가 window.location 과 동일한 인스턴스를 가지고 있는지 비교하거나, 두번째 인자인 프로퍼티 키를 비교해서 href 등의 값이라면, 원하는 값을 반환하도록 후킹 함수를 만들 수 있겠습니다.
function __internal_get__(owner, propertyKey) {
if (owner === window.location) {
return {
get href() { /* proxified 된 url을 기반으로 Router를 속이는 URL을 반환하는 로직 */ }
}
}
// ...
}마치며
글에 열거한 내용 이외에도 정말 많은 기술이 사용 되었는데, 아주 재밌는 경험 이었습니다. 혹여나 이러한 비슷한 기능을 하는 기능을 개발할 일이 있으시다면, 도움이 됐으면 좋겠습니다.
여기서 거의 라는 표현을 사용한 이유는, 제 짧은 식견에서 보자면 비슷한 맥락에서 사용하는 기법으로
integrity속성이 있을 수 있겠습니다. ↩︎예를 들면,
location.pathname을 읽어 현재 Route가 어떤 Route인지 감지하는 등의 동작이 있겠음. ↩︎
오늘은 고등학교 때 만들다 말았던 라이브러리를 얼추 마무리 지었다. Claude랑 같이 스펙 문서 만들고, 이를 바탕으로 작업하도록 했다. 당시에 하라는 FAT 덤프 파싱은 안 하고 Python에서 편하게 파싱하고 싶어서 만들기 시작했던 라이브러리고 취업하게 되서 이후로 안 봤었는데, Claude Code 덕분에 이제는 보내줄(?) 수 있을 것 같다.
근데 당시에 파서 콤비네이터를 몰랐어서 그랬고 지금은 파서 콤비네이터를 쓸 것 같다. 그리고 오늘 작업하면서 보게 된 건데 비슷한(?) 느낌으로 construct[1] 라는 라이브러리의 존재도 알게 되었다.
이제 Python을 잘 안 쓰고, 원래 시작점이었던 포렌식도 안 하니까 쓸 일은 없겠지만 그래도 당시 2019년 Hacktoberfest 시기에 필드 추가 기여도 받아보고 좋은 기억의 라이브러리였다.
https://github.com/moreal/pystructs/
학교 급식 메뉴 짜기 해보실 분
https://nutritionist-pi.vercel.app/

크리스마스를 맞아 크리스마스 트리... 가 아닌 Hackers' Pub 초대 트리를 꾸몄습니다.
기존 초대 트리는 작은 규모에서는 충분히 제 역할을 했으나 회원이 점차 늘어나면서 구조를 파악하기 어렵고, 페이지가 너무 길어져 변화가 필요하다고 생각했습니다. 다음 개편되는 Hackers' Pub의 초대 트리 페이지에서는 초대 관계를 잘 드러내면서, 많은 회원이 한 눈에 들어올 수 있도록 만들었습니다. Hackers' Pub의 회원은 앞으로도 많이 늘어날 예정이니까요. 그렇겠죠? 내년에도 Hackers' Pub에서 많은 분들을 만날 수 있기를, 더 풍성한 초대 트리를 볼 수 있기를 기대해봅니다.


deno install 명령어를 실행할 때 패치 패키지가 암묵적으로 npm 패키지로 덮어쓰여지는 버그를 수정하였습니다! 😊
Fixed a bug where patch packages were implicitly overwritten by npm packages when running the deno install command! 😊
deno install 명령어를 실행할 때 패치 패키지가 암묵적으로 npm 패키지로 덮어쓰여지는 버그를 수정하였습니다! 😊
[구인 커피챗 요청] 2025-12-26 ~ 2026-01-06 한국에 잠시 방문하는데, 좋은 개발자 분들을 만나고 싶습니다.
저는 펜시브 라는 미국 교육 AI 스타트업 CTO이고, 최근에 크게 투자유치를 하여 현재 초기 개발팀을 꾸리고 있습니다.
- 미국비자 지원받고 바로 샌프란시스코로 넘어오고 싶은 개발자 (미국에서 일하셔야 합니다!)
- 하루종일 학습에 대해서 생각하고 싶은 개발자
- 작은 팀으로 데카콘을 만들고 싶은 개발자
커피챗 연락주십시오: >> minjune@pensieve.co <<
펜시브 제품소개: https://claude.com/customers/pensieve
기술스택: typescript + react / fastapi + python / firebase / postgres

Optique 문서를 보다가 argument ordering 파트에서 프로퍼티가 나타난(? appear) 순서대로 파서가 동작(? consume)한다고 되어 있어서 Object 타입인데 이게 작성한 순서대로 Object.entries() 같은 곳에서 순회되기를 기대할 수 있나 의문이 들었다(Object가 Map같은 거라고 생각했어서).
아래와 같이 타고 가면:
20.1.2.5 Object.entries ( O )(User call)7.3.23 EnumerableOwnProperties ( O, kind )(called by2. Let entryList be ? EnumerableOwnProperties(obj, key+value).10.1.11 [[OwnPropertyKeys]] ( )(called by1. Let ownKeys be ? O.[[OwnPropertyKeys]]().)10.1.11.1 OrdinaryOwnPropertyKeys ( O )(called by1. Return OrdinaryOwnPropertyKeys(O).)
아래와 같은 대목을 만나는데:
- Let keys be a new empty List.
- For each own property key P of O such that P is an array index, in ascending numeric index order, do
- Append P to keys.
- For each own property key P of O such that P is a String and P is not an array index, in ascending chronological order of property creation, do
- Append P to keys.
- For each own property key P of O such that P is a Symbol, in ascending chronological order of property creation, do
- Append P to keys.
- Return keys.
만약 key가 array index가 아닌 문자열 혹은 Symbol이라면 프로퍼티 생성 발생의 오름차순 순서(? ascending chronological order of property creation)대로 순회(?)해야한다고 적혀있다.
아마.. 잘 못 찾아서 못 본 걸수도 있지만 chronological이나 creation 같이 검색했을때 스펙에서 이를 다루는 방법을 정의하지는 않는 것 같았다. 예를 들어, PropertyDescriptor이 auto increment 되는 고유 ID를 갖고 있어야 하고 이를 통해 정렬해야한다, 거나?
실제 구현을 보고 싶어서 GitHub에 있는 V8 미러로 가서 보니 key들을 OrderedHashSet으로 갖고 있는 듯 했다. 생각해보니 그러면 되네, 싶어서 더는 안 찾아봤다.
암튼 Optique 문서대로 생성 순서대로 동작할 것 같다!
We’re hiring! Looking for people who can write Windows kernel drivers. https://careers.theori.io/ko/o/191654
https://github.com/sonohoshi/sonomemo 최근에는 바이브코딩을 좀 해봤고, 제가 쓸 메모용 앱을 만들어봤습니다. 만들었다고 하는게 맞나? 바이브코딩이라는거 재밌더라고요. 사실 당연한 것 같습니다. 코딩에서 오는 아이디어 구현과 결과물이 나오는 재미는 취하고, 디버그하고 버그 잡는 힘든 일은 LLM이 해주는데 당연히 재미있겠죠. 어쨌거나 이 행위에 맛들려서 Rust 코드는 어떻게 쓰는지 볼 겸, 터미널 기반의 메모용 앱을 만들었습니다. 제가 쓰려고 만들었는데 생각보다 쓰는 트친들이 많이 생겨서 여기에도 올려봐요. 감사합니다.
@eatch잇창명 EatChangmyeong💕🐱 님 덕분에 @shikijs/vitepress-twoslash 패키지에 버그가 있다는 걸 알게 되어서, 이슈 트래커에 버그도 제보하고, 시간 내서 패치도 만들었다.
Big change coming to BotKit: multi-bot support! 
Currently, each BotKit instance can only run a single bot. We're redesigning the architecture to let you host multiple bots—both static and dynamically created—on a single instance.
The new API will look like this:
const instance = createInstance({ kv });
const greetBot = instance.createBot("greet", { ... });
const weatherBots = instance.createBot(async (ctx, id) => { ... });Check out the full design:
.kr 도메인이 두 배 이상 비싸져서... clig.kr 만 미리 다년 연장해놓고 다른 건 다른 TLD로 옮겨야지
어라 뭔가 단문에도 임시 저장 기능이 있네 (원래 있었나)

12月 6日 서울에서 開催되는 liftIO 2025에서 〈Optique: TypeScript에서 CLI 파서 컴비네이터를 만들어 보았다〉(假題)라는 主題로 發表를 하게 되었습니다. 아직 liftIO 2025 티켓은 팔고 있으니, 函數型 프로그래밍에 關心 있으신 분들의 많은 參與 바랍니다!

오늘 liftIO 2025에서 發表한 〈Optique: TypeScript의 타입 推論으로 CLI 有效性 檢査를 代替하기〉의 發表 資料를 共有합니다! 들어주신 모든 분들께 感謝 드립니다.

#rustlang hot take: We should rename .unwrap() to .or_panic(). (And .expect() to .or_panic_with().) "Unwrap" is a terrible name for the panicking function, especially since we also have things like .unwrap_or() and .unwrap_or_default() which never panic.
@morealLee Dogeon 밋업정보 공유드리려고 찾아보니까 제가 다른 개발밋업을 착각했네요. 덕분에 잘못등록한걸 발견했습니다
러스트 서울 밋업페이지는 여기에요
https://www.meetup.com/rust-seoul-meetup/

![]() @0xq0h3규영 앗 그렇군요, 공유 감사합니다!
@0xq0h3규영 앗 그렇군요, 공유 감사합니다!

러스트 궁금해서 러스트 서울 밋업 참가신청해두었다.
![]() @0xq0h3규영 오, 러스트 서울 밋업이 있나요?
@0xq0h3규영 오, 러스트 서울 밋업이 있나요?
Lee Dogeon shared the below article:
자연어에서의 재귀와 카탈랑 수
구슬아이스크림 @icecream_mable@hackers.pub
이 글은 자료구조와 알고리즘에서 중요한 개념인 재귀가 자연어에서 어떻게 나타나는지, 특히 통사론적 관점에서 인간 언어 능력의 창조성을 보여주는지를 탐구합니다. 'X의 Y의 Z의...'와 같은 소유격 조사를 사용한 문장 확장을 통해 재귀의 개념을 설명하고, 이러한 재귀가 카탈랑 수와 연관되어 있음을 지적합니다. 영어 예시를 통해 전치사구의 추가가 문장의 중의성을 증가시키고, 구문 분석의 가능한 경우의 수가 카탈랑 수열을 따른다는 것을 보여줍니다. 생성 규칙을 통해 명사구를 재귀적으로 확장하면서 중의성 계수가 카탈랑 수와 동일하게 나타남을 설명합니다. 마지막으로, 자연어의 중의성 해소는 산술 표현식과 달리 확률에 의존하며, 이는 전산/심리언어학에서 중요한 연구 주제임을 강조합니다. 이 글은 재귀의 개념이 자연어에서 어떻게 복잡하게 작용하는지, 그리고 그 중의성을 이해하는 것이 왜 중요한지를 흥미롭게 제시합니다.
Read more →Lee Dogeon shared the below article:
"expression"은 "표현식"이 아니라 그냥 "식"
蛇崩 (じゃくずれ) @ja@hackers.pub
이 글은 프로그래밍 용어 "expression"을 "표현식"이 아닌 간결한 "식"으로 번역해야 한다고 주장합니다. 필자는 "expression"이 수학에서 유래되었으며, 수학에서는 이미 "식"으로 번역되어 사용되고 있음을 지적합니다. 또한, 프로그래머들이 "표현식"을 선호하는 이유로 사전적 정의와 초·중등 교육에서 비롯된 선입견을 들지만, 실제로는 "식"으로 번역해도 의미 전달에 전혀 문제가 없다고 강조합니다. 오히려 "표현식"은 "representation"의 번역어인 "표현"과 혼동될 수 있으며, "정규표현식"과 같이 불필요하게 긴 용어를 만들어낼 수 있다고 비판합니다. 결론적으로, 필자는 "expression"을 "식"으로 번역하는 것이 더 정확하고 간결하며, 전산학 용어의 일관성을 유지하는 데 도움이 된다고 주장하며, "정규식"이라는 간결한 용어 사용을 옹호합니다.
Read more →얼마 전 웹서핑을 하다가 우연찮게 현재 앤트로픽에서 엔지니어이자 연구원으로 근무하고 있는 Nelson Elhage가 쓴 Computers can be understood(=컴퓨터는 이해가능하다)라는 글을 봤습니다. 다 읽고나니 이 분 마인드가 제가 평소에 CS 공부할 때랑 너무 비슷해서 공감이 가고 아직 CS 뉴비인 저한텐 굉장히 도움이 되는 한편, 이 마인드가 어떠한 단점을 또한 가져다주는지 잘 얘기하는 것 같아 (사실 읽으면서 뜬끔하는 게 많았음) 저만 알기엔 아까워서 이렇게 번역해서 올려봅니다.
번역된 글을 보려면 여기로 이동해주세용.
혹시나 오역 및 CS 용어에 문제가 있다면 언제든 알려주시면 감사하겠습니다.

그젠가 Hashnode as Headless CMS 글 보고 Ampcode로 바이브 코딩 해봤습니다. 글 목록이랑 태그 목록은 물론, 글 보여주는 부분에서는 리액션도 보여주고 번역된 버전이 있다면 볼 수 있도록 하였습니다.
https://moreal.github.io/hackerspub-astro-template/
Hackers' Pub 로컬 서버에 붙어서 빌드하고 수동으로 gh-pages에 배포했고, hackers.pub 에서 데이터를 가져다 쓰려면 올려놓은 GraphQL 관련 PR들이 반영되어야 합니다.

ampcode free 써보는데 이렇게 광고가 나온다 😲


대만의 COSCUP, 벨기에의 FOSDEM에 이어, 국내에서도 개인 및 소규모 오픈 소스 프로젝트를 위한 FOSS for All 컨퍼런스가 드디어 열립니다! 🇰🇷
오는 11월 8일(토), 광운대학교에서 개최되며 저도 이번 행사에서 발표자로 참여하게 되었습니다.
🗣️ 발표 주제: “식탁보 프로젝트 다섯돌, 바뀐 것과 바뀌지 않은 것”
식탁보 프로젝트가 세상에 나온 지 벌써 5년이 되었네요. 처음엔 AI가 없던 시대에 시작했지만, 이제는 AI가 세상을 바꾸고 있고, 식탁보도 그 여정 위에 있습니다.
다섯 해 동안의 변화와, 여전히 지켜온 가치들에 대해 진솔하게 이야기 나누려 합니다.
오픈 소스, 기술, 그리고 커뮤니티를 사랑하는 분들이라면 꼭 한 번 참석해보세요!
👉 참가 신청: https://event-us.kr/fossforall/event/110400
현장에서 함께 이야기 나눌 수 있기를 바랍니다. 🙌
#FOSSforAll #OpenSource #식탁보프로젝트 #TableCloth #광운대학교 #Conference

최근 (오픈소스) 프로젝트 관련해서 종종 연락을 받고 있습니다. 대체로, 검토해보겠다던 기능이 추가되는데 왜이렇게 늦어지냐는 내용으로 추정됩니다.
추정인 이유는 건너서 들은 것도 있기 때문입니다.
제가 이 글을 올리는 이유는 상당히 험한 말도 나왔다는걸 전해 들었기 때문입니다.
저는 외부의 어떠한 보수도 받지 않고 혼자서 정규업무 외 시간에 제 프로젝트의 개선과 이슈사항을 해결하고 있습니다.
최근에 개인적 사유로 커밋 빈도가 줄었던 것은 맞지만 그럼에도 우선순위가 높은 작업은 너무 늦어지지 않도록 노력했습니다.
제 프로젝트로 구축 및 운영을 하시는 분들이 있다고 하니 늘 감사하게 생각합니다만, 저는 이 일을 보수를 받고 하지 않습니다.
혹여 답답하신 분이라면 깃허브에 올라와있는 제 프로젝트 내용물을 통채로 복사해서 전문 개발 업체에 커스터마이징을 맡기시길 바랍니다.
그렇게 나온 결과물에 대해선 독점권 행사도 무리없이 행사하실 수 있도록 적극적으로 돕겠습니다. 감사합니다.
마인크래프트 내에 레드스톤으로 물리적으로 언어모델을 만든 사람이 나타남... 그러니까 간단한 디지털 회로도 아니거 언어모델을 만듬 ㅋㅋㅋ 외부 언어모델을 연결한것이 아닙니다;; 말그대로 트랜스포머를 구축해놨던데 세상은 넓고 천재는 많다... www.youtube.com/watch?v=VaeI...
I built ChatGPT with Minecraft...

인용 테스트 용 글
그렇습니다. 우울하지 않은 사람도 "우울할 때에는 상담하기"를 평소에 열심히 외워 둘 필요가 있습니다. 왜냐?
심리학에는 결핍의 덫(scarcity trap)이라는 개념이 있는데요. 사람은 시간이나 금전 등 어떤 자원이 결핍(scarce)되면, 심리적 압박을 받아 시야가 좁아집니다(tunnel vision). 이로 인해 올바른 결정과 실행을 못하게 됩니다. 그러면 자원의 결핍(scarcity)이 더 심해집니다.
이렇게 얘기하면 떠오르는 전형적인 예시가 있습니다. 열악한 노동 조건과 저임금에 시달리는 노동자가, 스트레스 때문에 퇴근 후 술이나 도박 등의 즉각적 쾌락에 돈과 시간과 건강을 다 탕진해 버리는 것이죠. 하지만, 높은 소득과 지위를 누리던 대기업 간부도 투신자살을 해서 충격을 주곤 합니다.
사람이 이 덫에 빠지게 되는 계기가 한두 가지가 아닙니다. 환경적 요인으로 인해 우울감이 발생하기도 하고, 반대로 우울감이 사회생활에 지장을 초래해 환경적 요인을 조성하기도 합니다. 그리고 어떤 식으로든 이 덫에 빠지면,
- 심리적 압박으로 시야가 좁아지고
- 그로 인해 어리석은 판단을 하게 되고
- 그 어리석은 판단으로 인해 더욱 궁지에 몰리고
- 심리적 압박이 더 커키고
- 더 어리석은 짓을 저지를 수가 있습니다.
이 악순환이 누적되면, 돈 많다는 사람들에게도, 똑똑하고 가방끈 길다는 사람들에게도, 얼마든지 비극이 일어나는 것입니다.
우울장애의 가장 큰 무서움이 이것입니다. 현대 사회가 개인에게 도움을 제공하는 모든 체계에는 전제가 있습니다. "개인이 적어도 이기적 동기는 잘 가지고 있을 것." 우울감이 지속되면 이 전제가 깨집니다. 스스로에게 이로운, 이기적인 판단조차 제대로 할 수 없게 됩니다.
그러니 "우울할 때에는 상담하기"를 기억합시다. 평소에 외워 두지 않으면, 우울할 때에 떠오르지 않습니다.
물론 한국은 우울장애에 대한 인지적 관점이 많이 부족한 사회입니다. 그러나 연락처 목록을 뒤져 보면 한두 명 정도는 믿고 이야기할 사람이 있을 것입니다.
주변 사람들을 못 믿겠다면, 일면식도 없는 전문가를 찾읍시다. 한국의 정신과 전문의나 상담심리사 등, 우울한 사람에게 도움을 줄 분들의 숙련도나 전문성은 뜻밖에도 전반적으로 뛰어난 편입니다. 믿고 도움을 청해 봅시다.
RE: https://gameguard.moe/notes/acyejg21pqcx00xl
역시 마니악한 주제로 라이트닝 토크하는 행사를 추가로 만들어야겠다
한동안 근황 공유를 못했네요... 내일 오프라인 모임에서 오랜만에 인사드릴게요! 밋업 소식 알려주신 ![]() @kodingwarriorJaeyeol Lee 감사합니당
@kodingwarriorJaeyeol Lee 감사합니당
Permission sets in config 필요하다고 생각했는데 나왔구나!