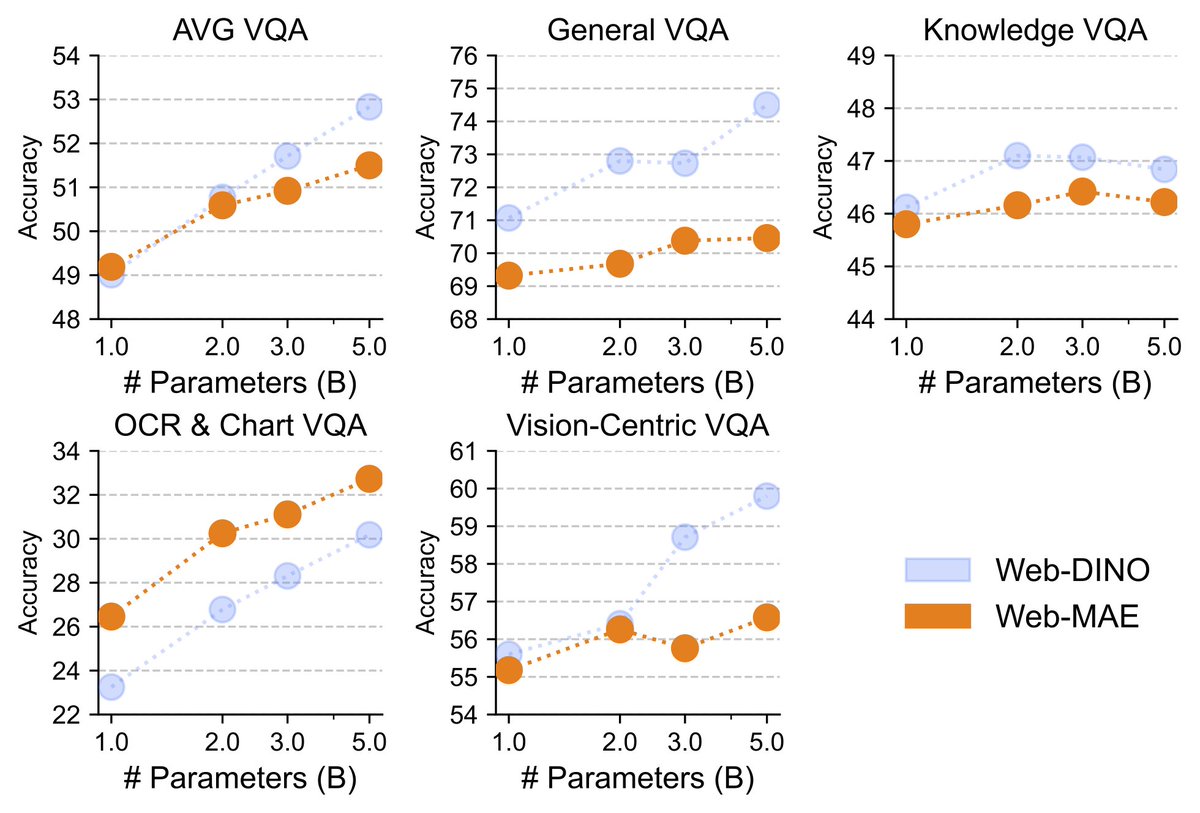
Pinned

[1/9] What happens when you treat vision as a first-class citizen during multimodal pretraining? To find out, we studied the design space of training Transfusion-style models that input and output all modalities, from scratch. Here is what we learned about visual representations,