Pinned

Words in. Worlds imagined. Actions out. 🤖🌎
DreamZero lets robots dream in pixels and act—via joint video + action prediction.
🔥2× better generalization than VLAs
⚡14B @ 7 Hz
🤝Cross-embodiment transfer (w/ 10–20 min video)
🦾New robot, 30 min play, zero-shot skills intact

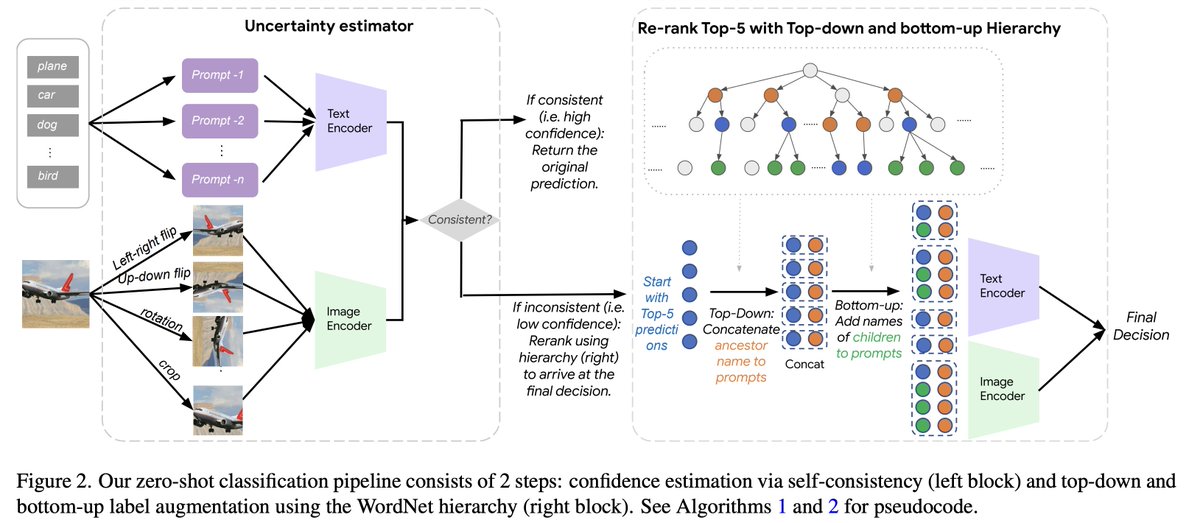
Introducing DreamZero 🤖🌎 from @nvidia
> A 14B “World Action Model” that achieves zero-shot generalization to unseen tasks & few-shot adaptation to new robots
> The key? Jointly predicting video & actions in the same diffusion forward pass
Project Page: dreamzero0.github.io

00:00