arxiv.org/pdf/2506.12779
From Experts to a Generalist: Toward General
Whole-Body Control for Humanoid Robots
training separate experts for different clusters of motions, (also treat sim2real separately), then distill to one WBC.
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control
beingbeyond.github.io/RLPF/
use physical simulation to verify and finetune text2motion models
arxiv.org/abs/2505.20829
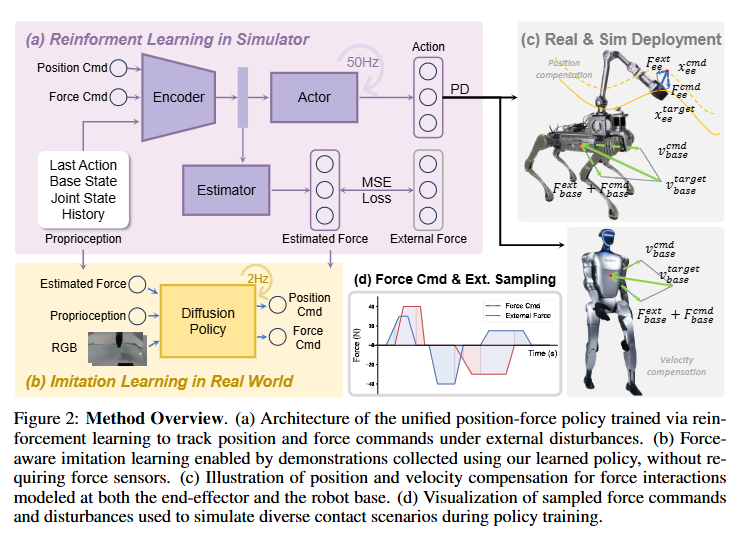
Learning Unified Force and Position Control for
Legged Loco-Manipulation
The hybrid interface of doing both position tracking and force control for the end effector enables more stable loco-mani especially for teleoperation.
Improving Vision-Language-Action Model with
Online Reinforcement Learning
arxiv.org/abs/2501.16664
online RL for VLA is unstable, so the authors do iterative RL here to stabilize it.
arxiv.org/pdf/2508.21043
HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning
Model based planning (with mocap perception) + RL stylistic tracking
AnyDexGrasp: Learning General Dexterous Grasping
for Any Hands with Human-level Learning Efficiency
graspnet.net/anydexgrasp/
amazing. title explains all.
potential contacts as the intermediate layer.
Latent Action Diffusion for Cross-Embodiment Manipulation
arxiv.org/pdf/2506.14608
shared latent space DP with different en/decoders for different morph
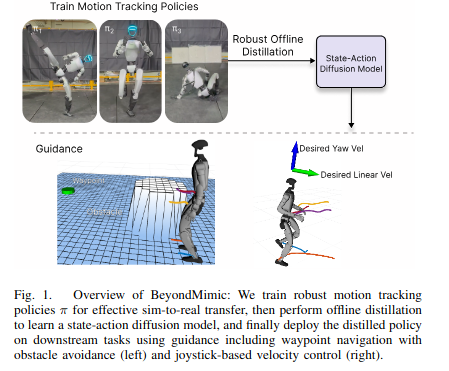
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
arxiv.org/abs/2508.08241
train tracking policies -> distill with diffusion -> use custom scores for downstream tasks without retraining.
It's the followup of their previous SIGGRAPH work at RAI
Narrate2Nav: Real-Time Visual Navigation with Implicit Language Reasoning in Human-Centric Environments
arxiv.org/abs/2506.14233
teacher VLA (with language narration of scene as input) + student distillation to implicitly learn the cues with real-time inference.