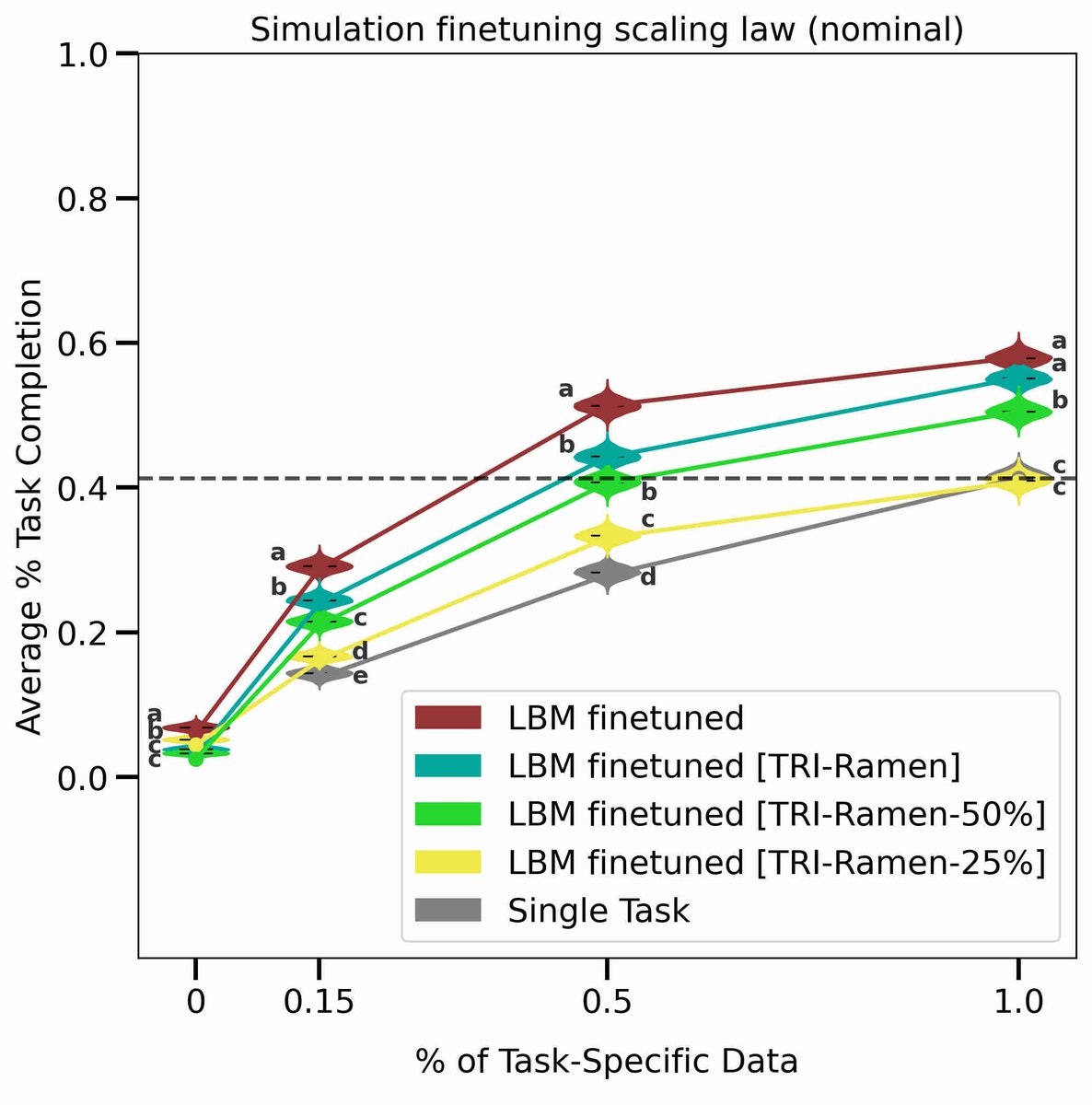
TRI's latest Large Behavior Model (LBM) paper landed on arxiv last night! Check out our project website: toyotaresearchinstitute.github.io/lbm1/
One of our main goals for this paper was to put out a very careful and thorough study on the topic to help people understand the state of the