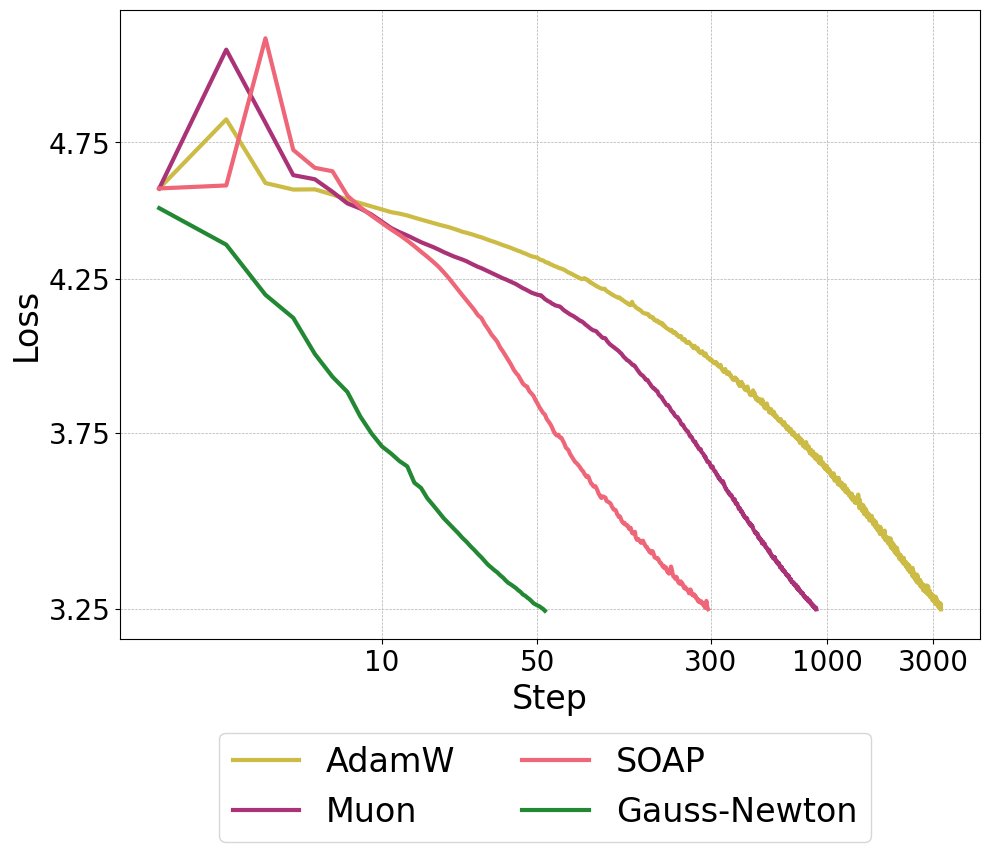
1/8 Second Order Optimizers like SOAP and Muon have shown impressive performance on LLM optimization. But are we fully utilizing the potential of second order information? New work: we show that a full second order optimizer is much better than existing optimizers in terms of