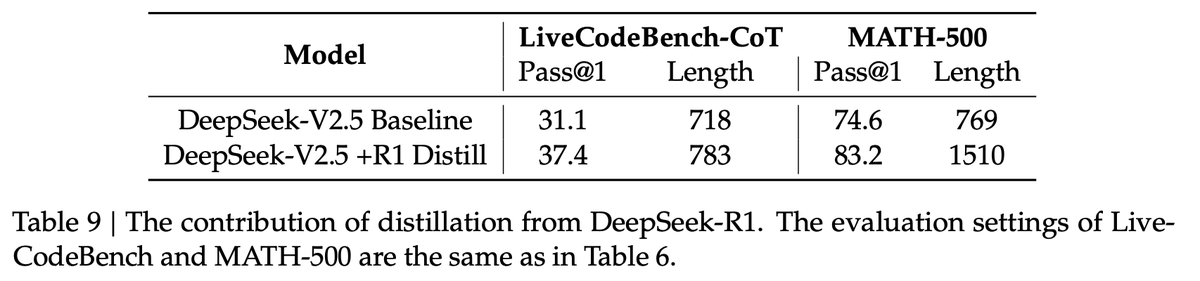
Pinned

New post: how we do evals at @cursor_ai. Takeaways:
1. Online metrics from real Cursor requests provide construct validity
2. CursorBench: a dynamic offline suite distilled from online learnings
3. Multi-axes evals -- correctness, efficiency, agent interaction behavior

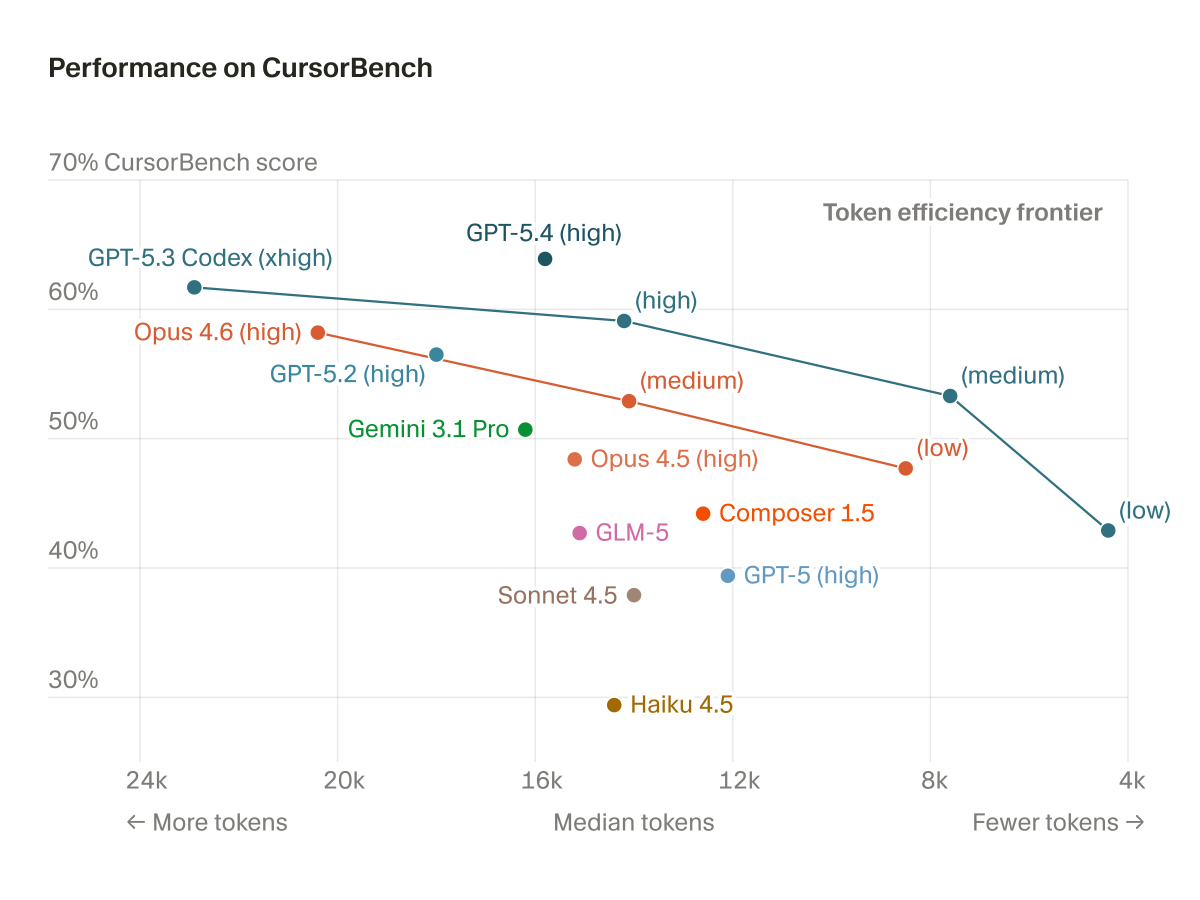
We're sharing a new method for scoring models on agentic coding tasks.
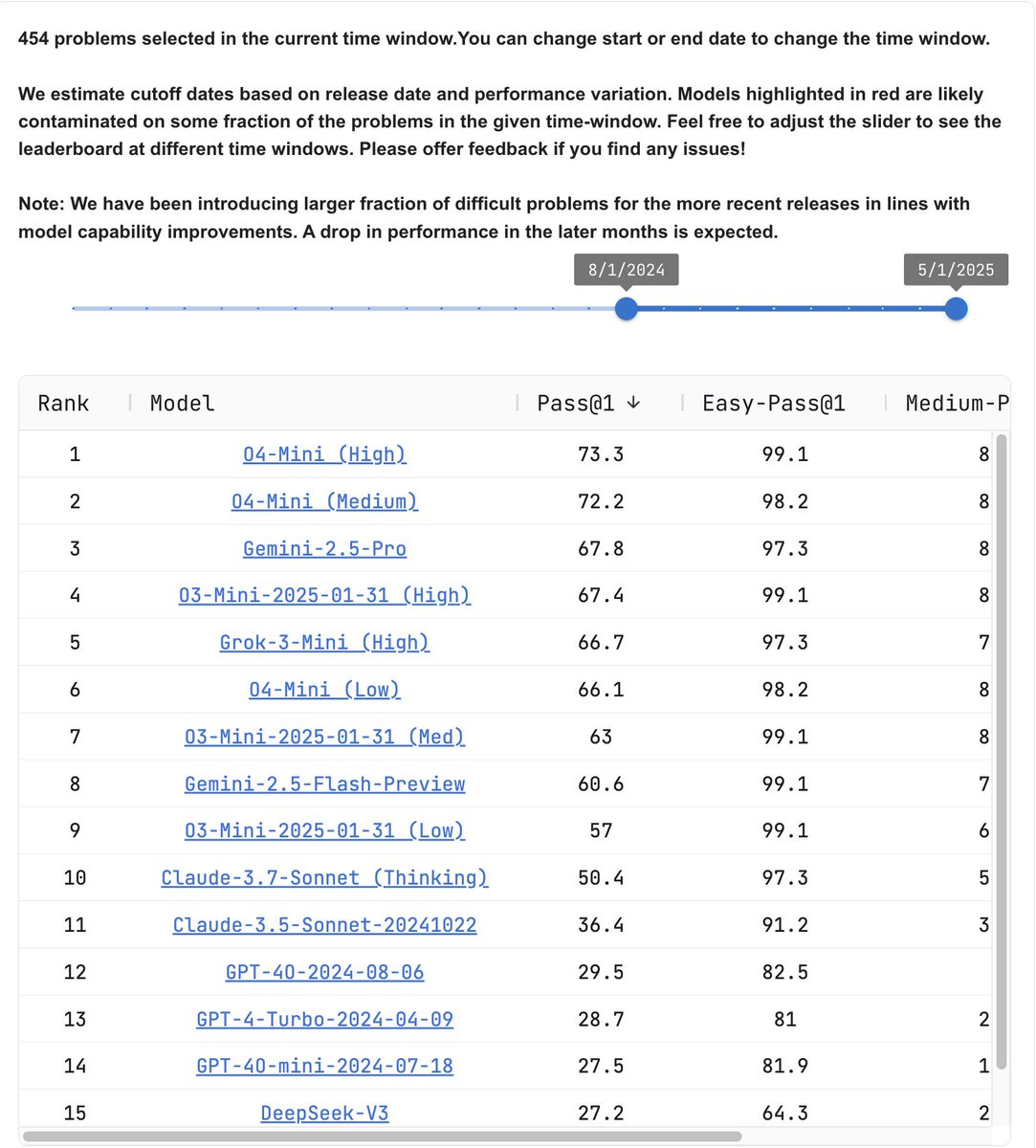
Here's how models in Cursor compare on intelligence and efficiency: