This year @WecoAI will be at the @aiDotEngineer World's Fair.
We'll host a hands-on autoresearch workshop on June 29.
And I'll give a talk on July 1.
Looking forward to chatting with old and new friends there!
Production autoresearch is usually killed by reward hacking or side effects.
But we still see a pattern that survives: the unit been evaled is functional or near-functional code.
Some examples: (1/5)🧵
We're thrilled to welcome Vayum Arora to Weco AI as our growth lead!
We couldn't be more excited to bring on Vayum's mix of frontier engineering and business instinct as we continue to grow.
Welcome to Weco, @vayum_arora!
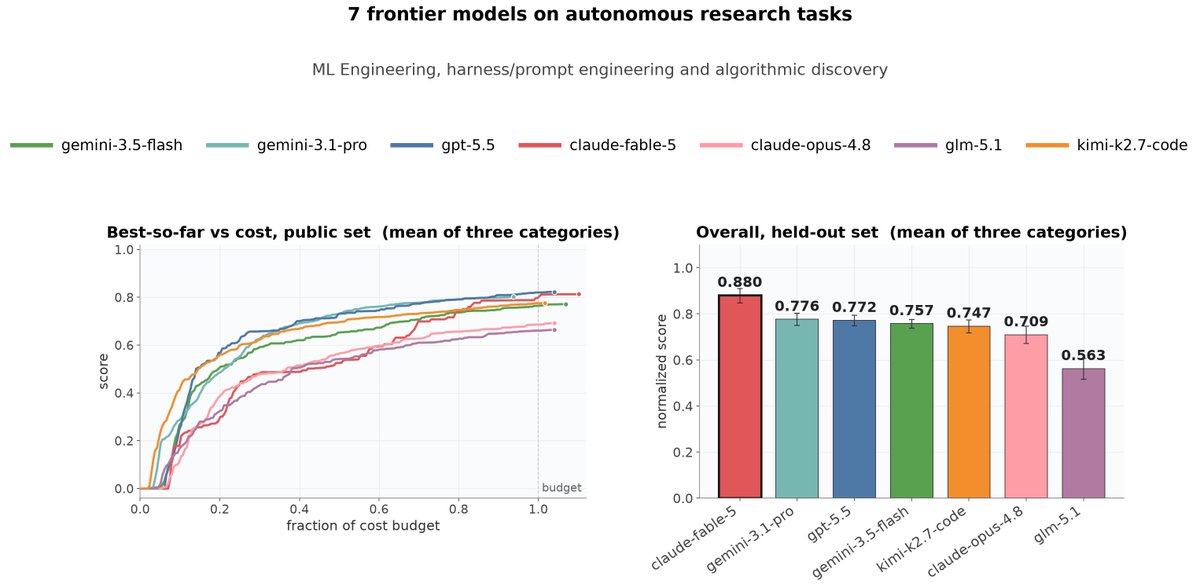
We benchmarked 7 frontier models on 3 categories of autoresearch tasks: ML engineering, harness/prompt engineering, and algorithmic discovery.
Fable-5 won overall even under cost constraint, but on ML engineering, the open model Kimi-K2.7-Code surpassed frontier models.🧵(1/5)
Haha, thanks for remembering Weco Observe!
We’ve been working in the autoresearch space for about three years, though, before it even had this name. It actually started with:
OpenAI ran a hiring challenge, but the top candidate was one they couldn’t hire: our autonomous research agent, Aiden.
In Parameter Golf, Aiden ran for 22 days, and out-outperformed all 1,016 other researchers: 🧵 (1/8)
Introducing SpecBench: the first benchmark for measuring reward hacking in long-horizon coding agents.
Key finding: reward hacking is driven not by test coverage, but by the gap between task difficulty and model capability: 🧵(1/8)
Some practical suggestions for anyone running Ralph loop, /goal, autoresearch or weco:
1. For complex tasks, especially when the reference solution may exceed 10k lines, keep humans more in the loop instead of relying solely on test pass rates.
2. For complex tasks, choose the
Comparing Opus 4.7 vs 4.6 on AutoResearch.
Opus 4.7 isn't significantly more sample-efficient, but is surprisingly cheaper due to fewer function calls.
Details in 🧵(1/4)
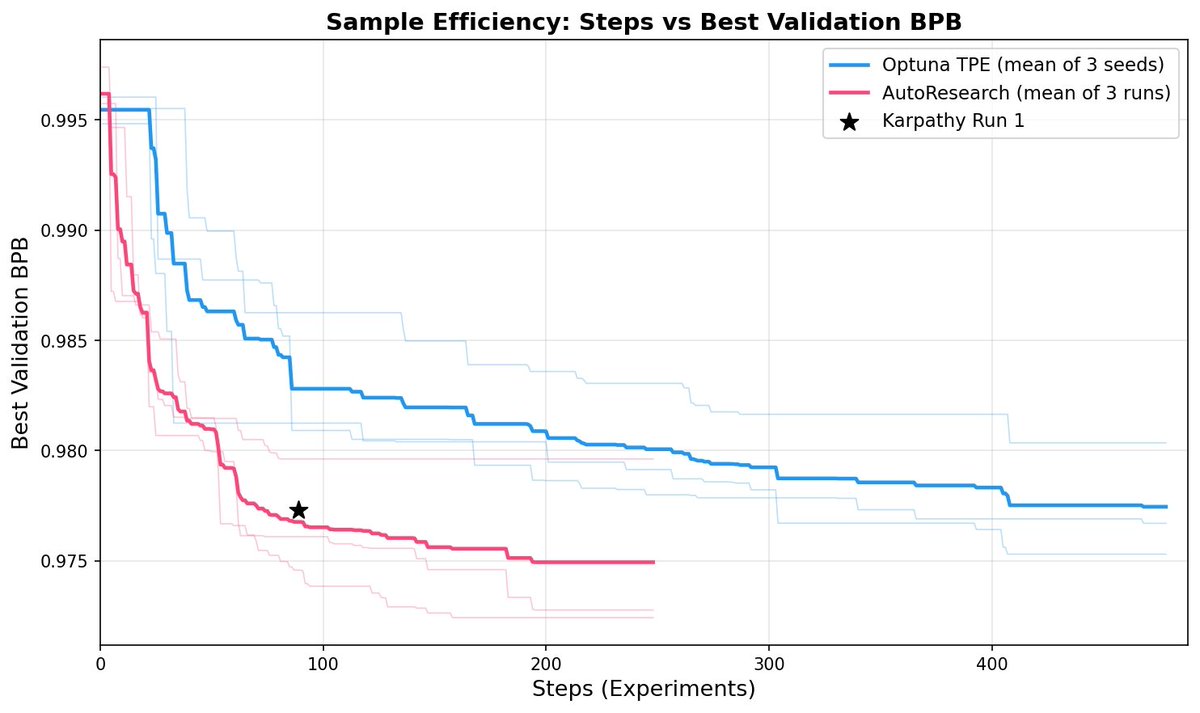
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
Is autoresearch really better than classic hyperparameter tuning?
We did experiments comparing Optuna & autoresearch.
Autoresearch converges faster, is more cost-efficient, and even generalizes better: 🧵(1/6)
AutoResearch is a general purpose code optimizer, and math formulas can also be expressed as code.
The emerging use case of formula discovery is really interesting, give it empirical data and let the agent search for math expressions that fit.
Examples 🧵(1/5):
The replies surfaced a lot of amazing use cases, more than I expected. There must be more outside my radar.
Creating a curated list here, PRs welcome for your own use cases, ideally with traces so the community can verify!
github.com/WecoAI/awesome…
Autoresearch has been out for 2 weeks. The community is trying to apply it to everything with a measurable metric, here are some successful attempts: 🧵 (1/6)