All products are now available to order! $45k for tinybox green with 5090s, and we have two variants of the tinybox pro v2, one with 5090s and one with RTX6000 Blackwells (that's a whopping 768 GB of RAM)
RIP, no future in Mojo now. Qualcomm is not a good steward for open source software. Modular raised too much money, should have stayed leaner to have a chance at winning.
We’re excited to announce that Modular has entered an agreement to be acquired by @Qualcomm. The future of unified compute has never been stronger. Read the full announcement: modular.com/blog/qualcomm-…
All day using GLM 5.2. Didn't miss much. First open model that passes the bar as a daily driver. Things are not going to be the same.
Damn, now I want to buy some serious hardware.
I have on good authority that GLM 5.2 is running at 120 tok/s across two networked Blackwell tinyboxes. $150k and that setup can be yours, either 2x tinybox or 1x tinybox pro. Never pay the cloud again.
We live in a weird time of overhyping slop that will be forgotten about in weeks. Linux and Python are both from 1991. LLVM started as research project in 2000.
We want to build the foundations of silicon life. Software that lives for 50 years. There's time to make it perfect.
The tinygrad from the book has ~40 ops.
ALU: 10 (base) + 10 (compound)
movement: 6 (base) + 2 (STACK+BITCAST) + INDEX
source: BUFFER/PARAM/CONST
data: LOAD/STORE/AFTER -- how/when it moves
lambda lift: CALL
loops: RANGE/END
scan: REDUCE -- needed?
final: SINK -- group STORE
Every UOp is a tuple: (op, srcs, arg?)
shape, dtype, device, addrspace are recursively computed properties.
This is what happens if you just keep refactoring. LLVM IR is good, but parts look like they locked it in before it was done. We value beauty over speed and features.
STORE is the only op with any observable side effects. This IR spans from the PyTorch level graph down to the level of LLVM IR.
It's notably not Turing complete.
Artificial Analysis just added GLM 5.2 to their open vs closed frontier timeline, here's a flipped version which gives the lag time of OSS perf on their intelligence index
.@realGeorgeHotz doesn’t follow the script.
From jailbreaking the iPhone at 17 and reverse-engineering the PS3 to building open-source self-driving technology at @comma_ai, he's consistently pushed the boundaries of what's possible.
Now, as founder of @__tinygrad__, he’s
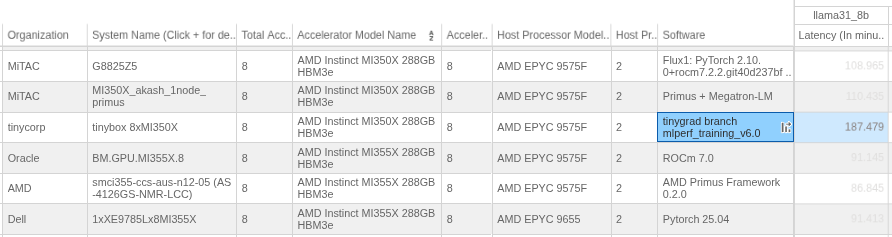
We are on the MLPerf board with AMD MI350X training Llama 8B. This is with our driver, runtime, kernels, and training loop. 405B next MLPerf, along with a better time on 8B (tinygrad currently at 170 min).