Pinned

Is pixel prediction the best way to build a world model?
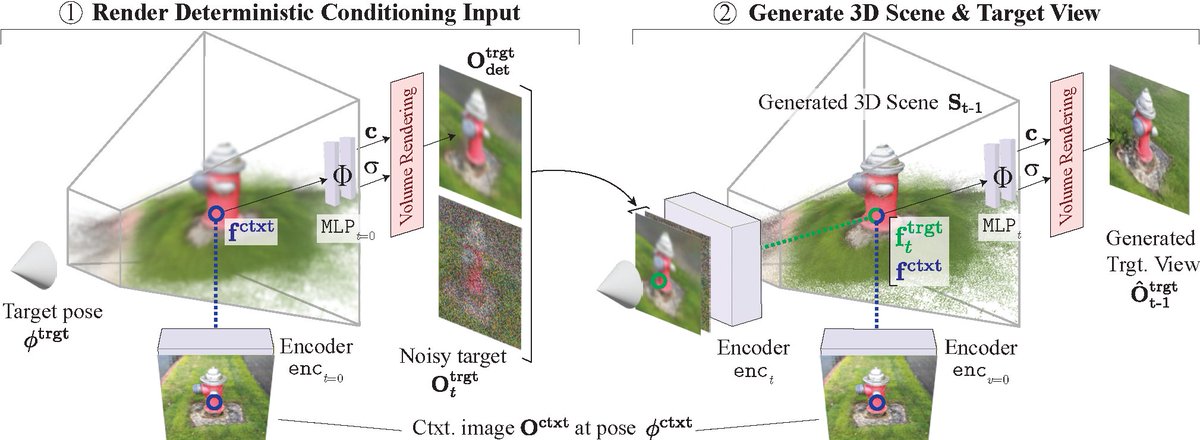
Check out VDAWorld, an alternative path to building interpretable, editable, and physically grounded world models.
We use a VLM to build a simulation of the scene with the help of a computer vision toolbox.

00:00