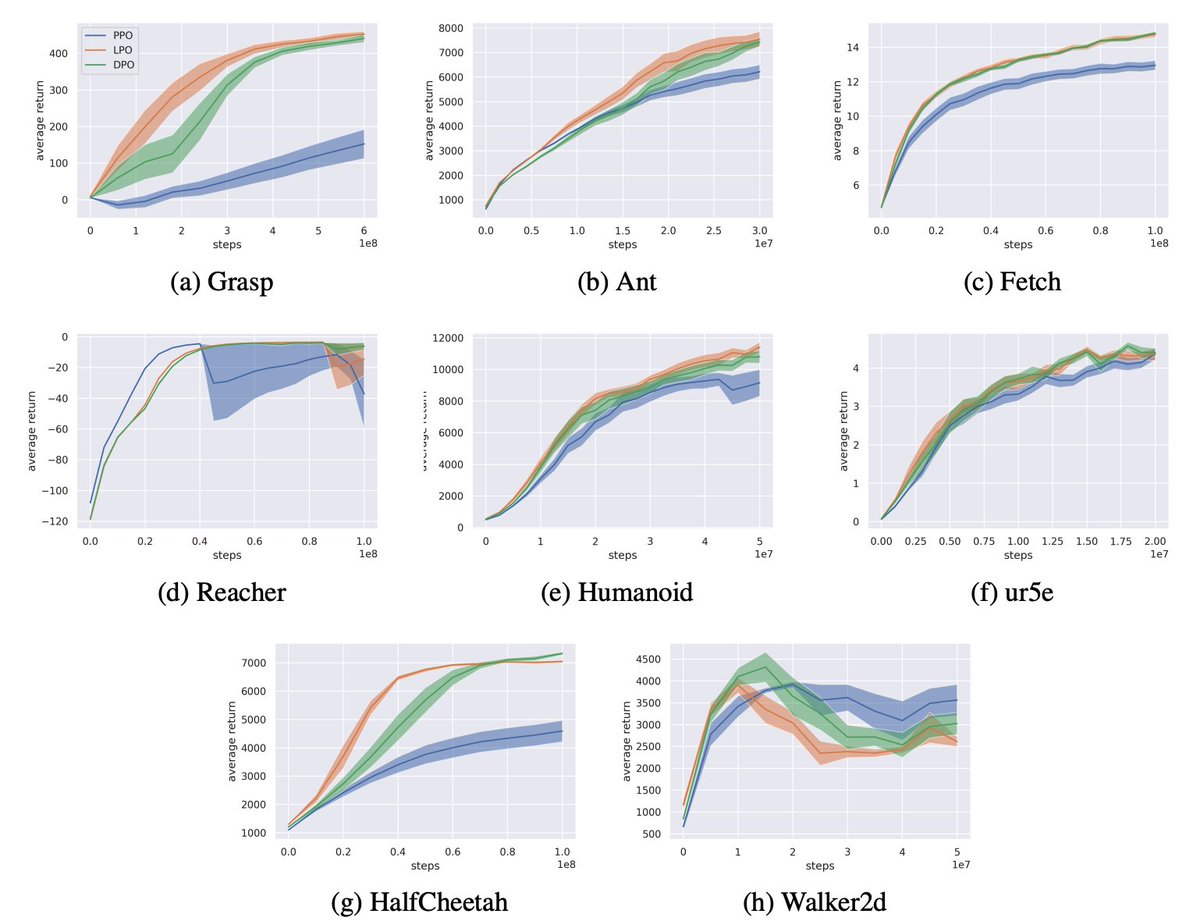
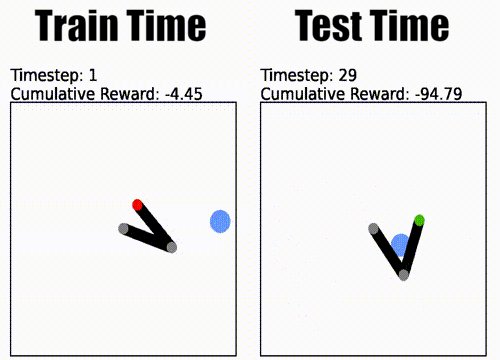
Pinned

Excited to share The AI Scientist! We use LLMs to autonomously come up with research ideas, implement them, do literature search, write them up, and review them -- producing full-length papers on AI without human intervention.
Co-led with @cong_ml and @RobertTLange

Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!
sakana.ai/ai-scientist/
From ideation, writing code, running experiments and summarizing results, to writing entire papers and conducting peer-review, The AI