DeepSeek R1 (the full 680B model) runs nicely in higher quality 4-bit on 3 M2 Ultras with MLX.
Asked it a coding question and it thought for ~2k tokens and generated 3500 tokens overall:
DeepSeek R1 671B running on 2 M2 Ultras faster than reading speed.
Getting close to open-source O1, at home, on consumer hardware.
With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw)
Just in time for the holidays, we are releasing some new software today from Apple machine learning research.
MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!)
Code: github.com/ml-explore/mlx
Docs: ml-explore.github.io/mlx/build/html…
DeepSeek R1 distilled to Qwen 1.5B easily runs on my iPhone 16 with MLX swift.
Here's the 4-bit model reasoning entirely on device at almost 60 toks/sec:
The new 1 Trillion parameter Kimi K2 Thinking model runs well on 2 M3 Ultras in its native format - no loss in quality!
The model was quantization aware trained (qat) at int4.
Here it generated ~3500 tokens at 15 toks/sec using pipeline-parallelism in mlx-lm:
Quantized Gemma 2B runs pretty fast on my iPhone 15 pro in MLX Swift.
code & docs: github.com/ml-explore/mlx…
Comparable to GPT 3.5 turbo and Mixtral 8x7B in
@lmsysorg benchmarks but runs efficiently on an iPhone. Pretty wild.
Read a bit about Grokking recently. Here's some learnings:
"Grokking" is a curious neural net behavior observed ~1 year ago (arxiv.org/abs/2201.02177).
Continue optimizing a model long after perfect training accuracy and it suddenly generalizes.
Figure:
Wow, DeepSeek R1 Distill Qwen 7B (in 4-bit) nailed the first hard math question I asked it.
Thought for ~3200 tokens in about 35 seconds on M4 Max with mlx-lm.
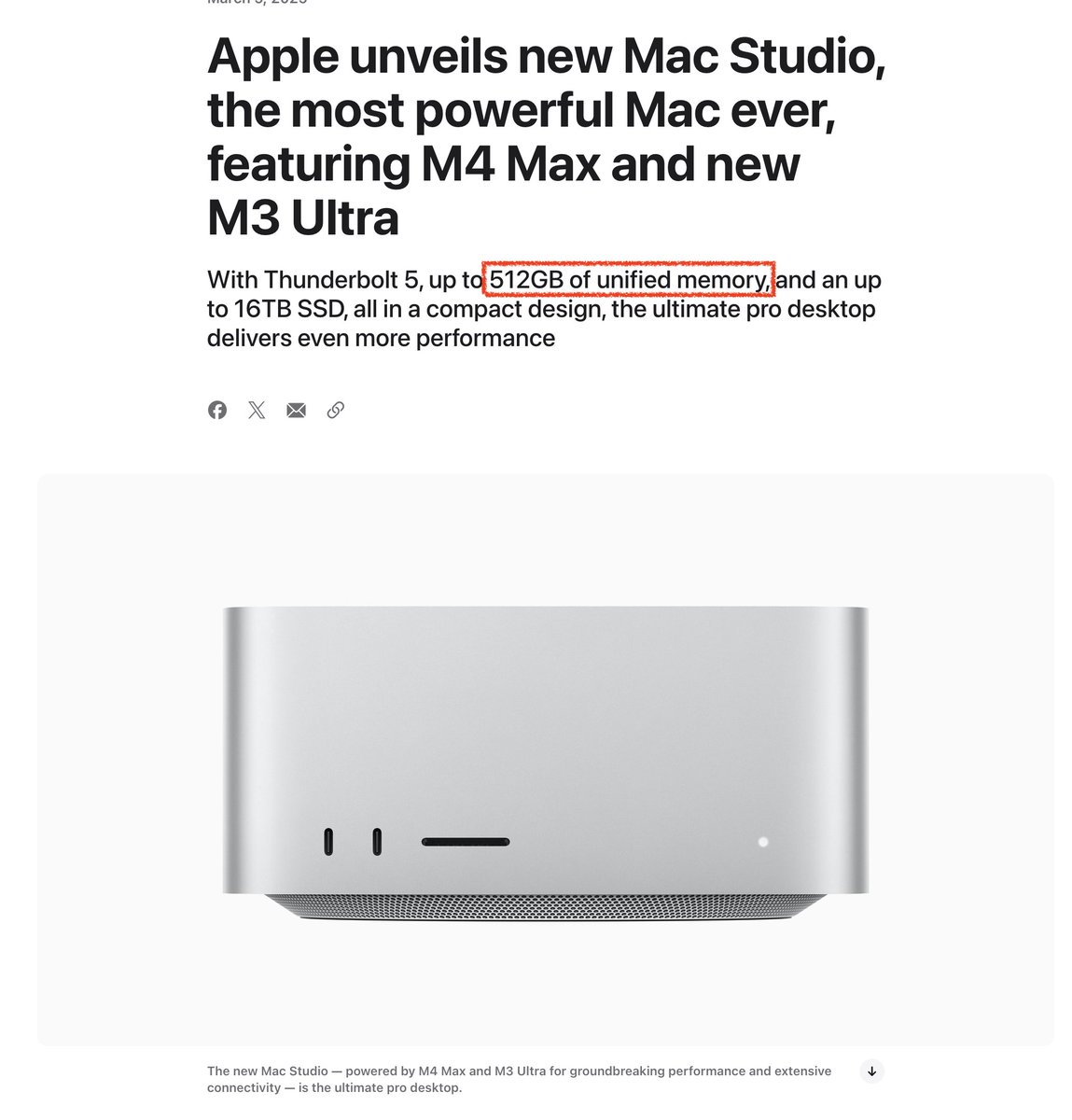
The new Kimi K2 1T model (4-bit quant) runs on 2 512GB M3 Ultras with mlx-lm and mx.distributed.
1 trillion params, at a speed that's actually quite usable:
🚀 Hello, Kimi K2! Open-Source Agentic Model!
🔹 1T total / 32B active MoE model
🔹 SOTA on SWE Bench Verified, Tau2 & AceBench among open models
🔹Strong in coding and agentic tasks
🐤 Multimodal & thought-mode not supported for now
With Kimi K2, advanced agentic intelligence