"That's when they come to open-source models, that's when they come to Baseten, that's when they come to post-train models on Baseten, to be able to do it better, faster, and cheaper. That's when you get both intelligence everywhere and unit economics that make sense for your
Thanks to @EdLudlow for having us on Bloomberg Tech yesterday to talk about our latest fundraise and the growing number of companies owning their open and specialized models.
Excited to be a day 0 launch partner for BioNeMo, NVIDIA's new, fully-open agent toolkit for scientific workflows!
All 10 BioNeMo NIMs are available in our model library. Learn more in our announcement: baseten.co/blog/nvidia-bi…
Science is entering a new era - one where AI agents can do scientific work.
🧬 Today NVIDIA is launching the BioNeMo Agent Toolkit - an open, agent-ready toolkit that gives any AI agent callable tools for protein structure prediction, molecular docking, generative chemistry,
Tutorial on how to use GLM-5.2 in Claude Code (bookmark this)
~4.5x faster & ~5x cheaper compared to Opus 4.8!
1. Install the latest Claude Code
npm install -g @Anthropic-ai/claude-code
2. Create an account at baseten.co.
3. Grab an API Key from
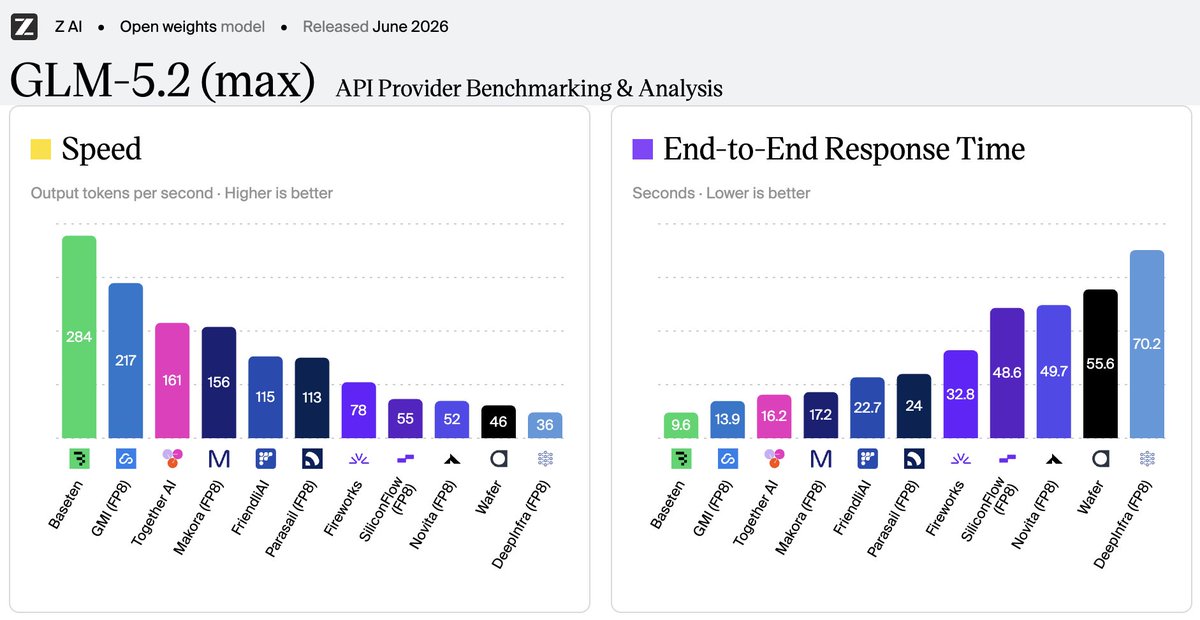
We have the fastest GLM-5.2 deployment on the market: >280 tok/s and <0.8s ttft, according to Artificial Analysis. This same performance carries across all post-trained variants.
These aren’t vanity metrics. Optimizations like these save our customers tens of millions of dollars
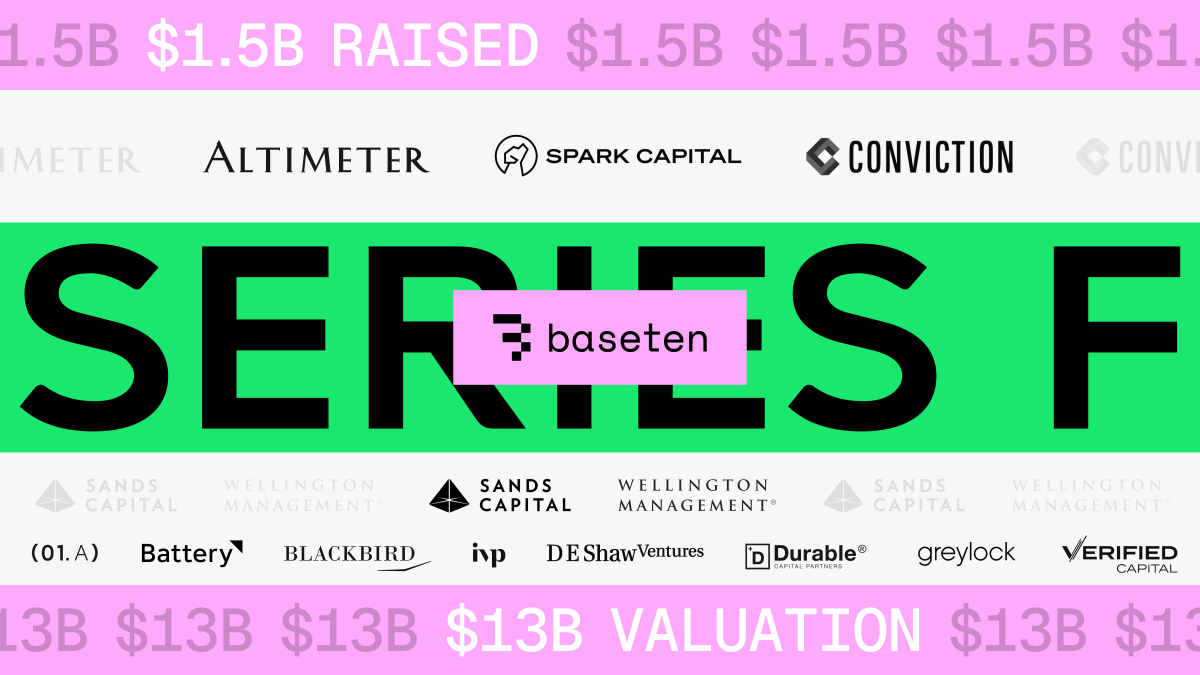
We closed our Series F today at a $13B valuation.
Our inference business grew 20x in the last year. I want to explain why:
The growth comes from a shift I think is permanent: companies want to own their intelligence layer. Instead of relying exclusively on closed models, teams
The GLM moment is going to be bigger than the DeepSeek moment.
Baseten has the fastest inference on the best open-weight model. >280 tps and <0.8 ttft.
We’re excited to announce our $1.5B Series F.
Baseten exists to help companies own their intelligence and run AI products in production with speed, reliability, and control. As we enter this next chapter, three things are clear:
1. Customers like Abridge, Clay, Cursor, Decagon,
@baseten model performance team is absolutely cracked. @Zai_org GLM 5.2 is now 4x faster running at full 1M context!
Already available to use in your favorite coding harnesses, here it is COOKING in @FactoryAI Droid and @opencode
Docs for how to get it in comments
@baseten model performance team is absolutely cracked. @Zai_org GLM 5.2 is now 4x faster running at full 1M context!
Already available to use in your favorite coding harnesses, here it is COOKING in @FactoryAI Droid and @opencode
Docs for how to get it in comments
Most supervised fine-tuning (SFT) studies run on generic data. Ours run on production tasks, paired with evals our team spends weeks building.
New post-training research from our team here.
1/ We fine-tune a lot of customer models, so we decided to systematically try and figure out some best practices for finetuning. SFT isn't sexy, but it's still important. We vary one SFT lever at a time across 2 model families, dense + MoE to 235B, on 4 real-world customer