
Pinned

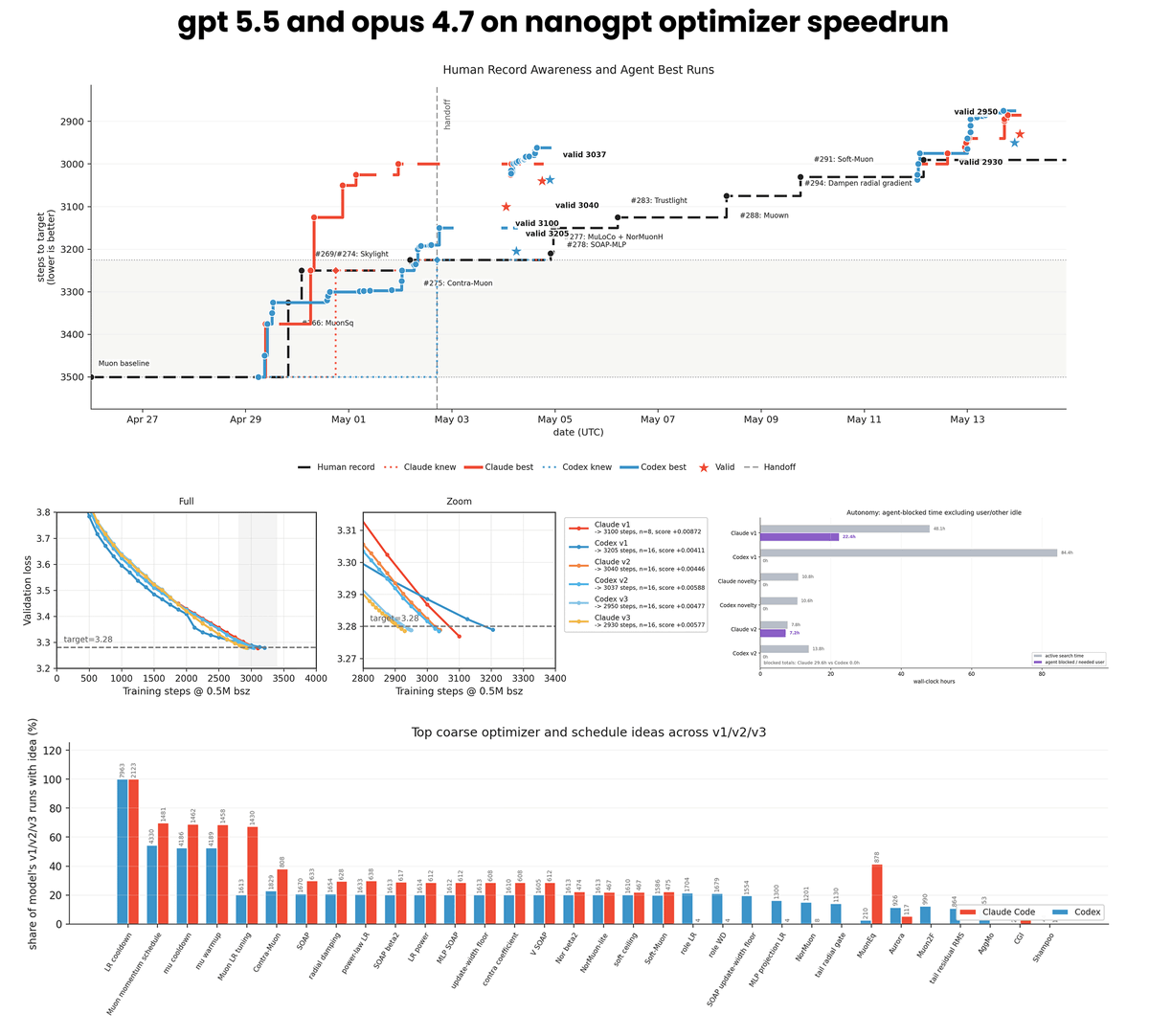
we let opus 4.7 and gpt 5.5 run on the nanogpt optimizer speedrun: ~10k runs, 14k H200 hours, 23.9B tokens. opus hits 2930, codex 2950, both beating the human baseline of 2990. we cover claude autonomy failures, codex high compute usage, and much more
primeintellect.ai/auto-nanogpt

Automating AI research is the next major step in AI
We let Claude Code (Opus 4.7) and Codex (GPT 5.5) run autonomously on the nanoGPT speedrun optimizer track using our idle compute. ~10k runs, ~14k H200 hours
Opus now holds the record at 2930 steps vs the 2990 human baseline