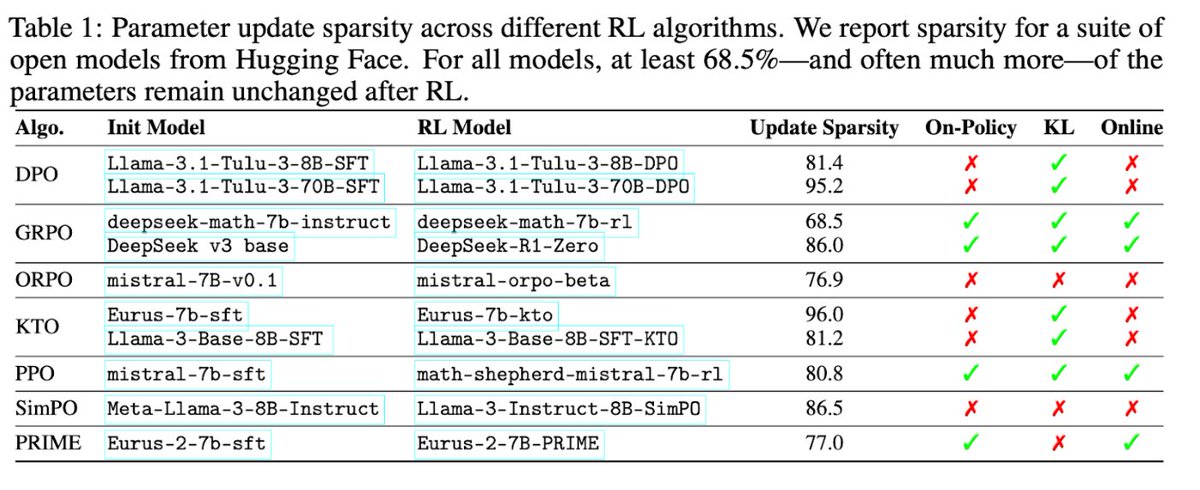
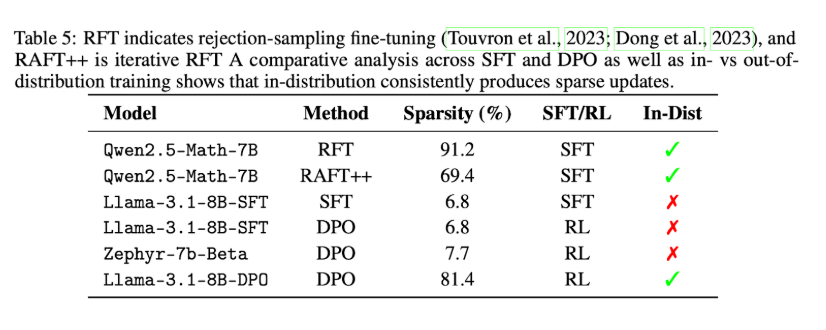
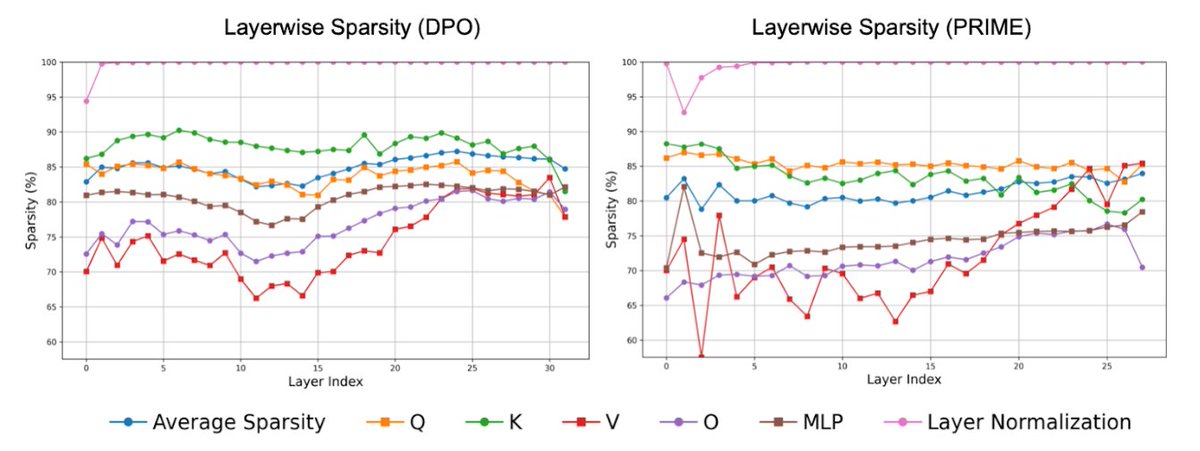
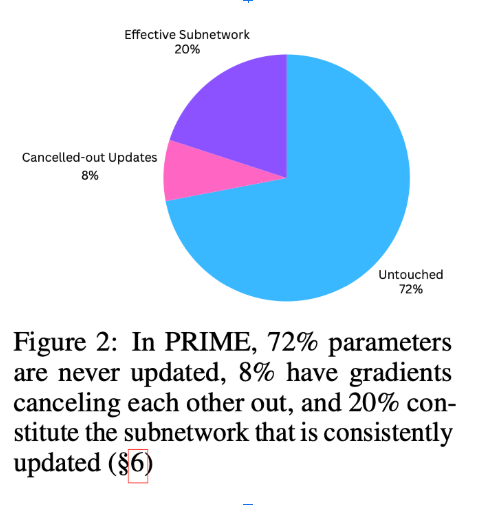
Pinned

🚨New Blog Alert: Is AdamW an overkill for RLVR?
We found that vanilla SGD is
1. As performant as AdamW,
2. 36x more parameter efficient naturally. (much more than a rank 1 lora) 🤯
Looks like a "free lunch".
Maybe It’s time to rethink the optimizers for RLVR 🧵