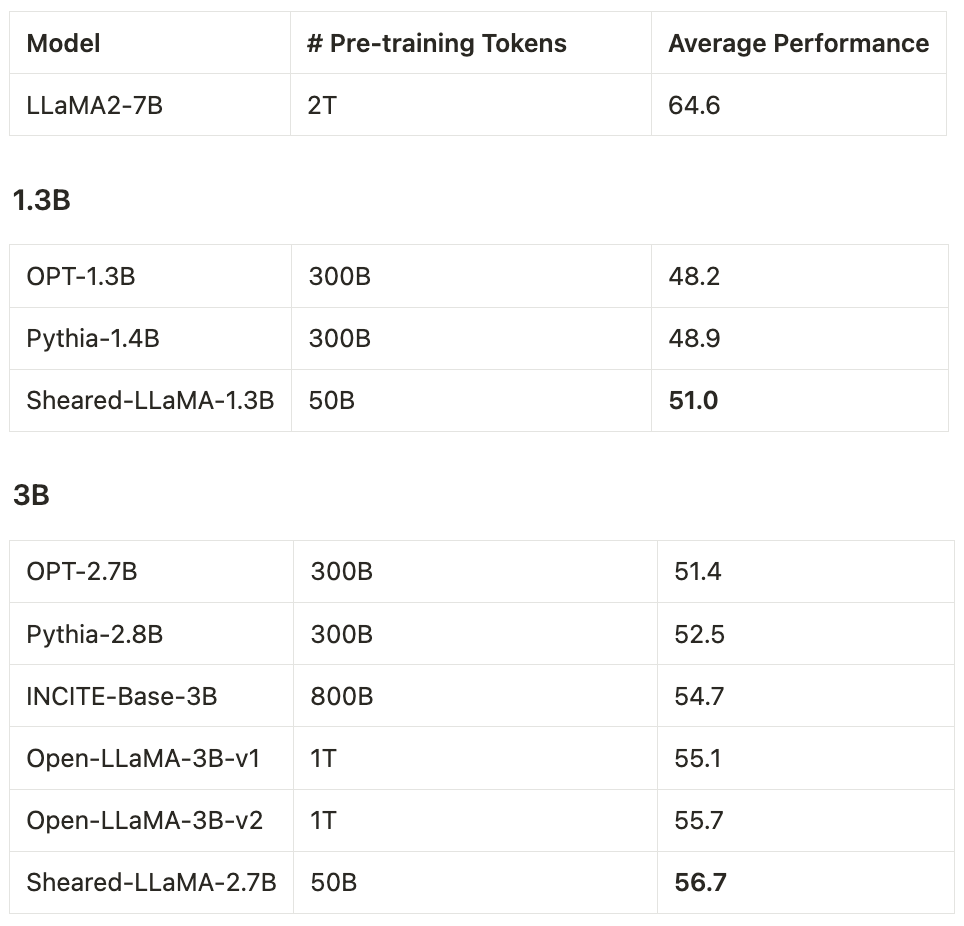
We release the strongest public 1.3B and 3B models so far – the ShearedLLaMA series.
Structured pruning from a large model to a small one is far more cost-effective (only 3%!) than pre-training them from scratch!
Check out our paper and models at: xiamengzhou.github.io/sheared-llama/
[1/n]