pydantic-resolve turns pydantic from a static data container into a powerful composable component.

Project description




pydantic-resolve is a Pydantic based approach to composing complex data models without imperative glue code. It elevates Pydantic from a static data container to a powerful, flexible computation layer.
from pydantic-resolve v2 alpha,
ErDiagramare introduced, your can declare Entity Relationship and their default dataloader in application level, then loaders will be applied automatically.
It introduces resolve hooks for on-demand data fetching, and post hooks for normalization, transformation, and reorganization to meet diverse requirements.
Installation
# latest v1
pip install pydantic-resolve==1.13.5
# v2
pip install pydantic-resolve
Starting from pydantic-resolve v1.11.0, both pydantic v1 and v2 are supported.
Starting from pydantic-resolve v2.0.0, it only supports pydantic v2, support of pydantic v1 and dataclass are dropped.
everything else are backward compatible.
Quick start
get teams with sprints and memebers, build data struct on demand, using dataloader to batch load related data on-demand.
from pydantic_resolve import Loader, Resolver
class Sample1TeamDetail(tms.Team):
sprints: list[Sample1SprintDetail] = []
def resolve_sprints(self, loader=Loader(spl.team_to_sprint_loader)):
return loader.load(self.id)
members: list[us.User] = []
def resolve_members(self, loader=Loader(ul.team_to_user_loader)):
return loader.load(self.id)
@route.get('/teams-with-detail', response_model=List[Sample1TeamDetail])
async def get_teams_with_detail(session: AsyncSession = Depends(db.get_session)):
teams = await tmq.get_teams(session)
teams = [Sample1TeamDetail.model_validate(t) for t in teams]
teams = await Resolver().resolve(teams)
return teams
New in V2.0
ErDiagram was introduced, which provides a clear ER description for the model and the default dataloader used.
Once after we have it defined source code:
diagram = ErDiagram(
configs=[
ErConfig(
kls=Team,
relationships=[
Relationship( field='id', target_kls=list[Sprint], loader=sprint_loader.team_to_sprint_loader),
Relationship( field='id', target_kls=list[User], loader=user_loader.team_to_user_loader)
]
),
ErConfig(
kls=Sprint,
relationships=[
Relationship( field='id', target_kls=list[Story], loader=story_loader.sprint_to_story_loader)
]
),
ErConfig(
kls=Story,
relationships=[
Relationship( field='id', target_kls=list[Task], loader=task_loader.story_to_task_loader),
Relationship( field='owner_id', target_kls=User, loader=user_loader.user_batch_loader)
]
),
ErConfig(
kls=Task,
relationships=[
Relationship( field='owner_id', target_kls=User, loader=user_loader.user_batch_loader)
]
)
]
)
Then the code above can be simplified as, The required dataloader will be automatically inferred.
class Sample1TeamDetail(tms.Team):
sprints: Annotated[list[Sample1SprintDetail], LoadBy('id')] = []
members: Annotated[list[us.User], LoadBy('id')] = []
How it works
The resolution lifecycle is kind like lazy evaluation: data is loaded level by level through the object.
Compared with GraphQL, both traverse descendant nodes recursively and support resolver functions and DataLoaders. The key difference is post-processing: from the post-processing perspective, resolved data is always ready for further transformation, regardless of whether it came from resolvers or initial input.

pydantic class can be initialized by deep nested data (which means descendant are provided in advance), then just need to run the post process.

Within post hooks, developers can read descendant data, adjust existing fields, compute derived fields.
Post hooks also enable bidirectional data flow: they can read from ancestor nodes and push values up to ancestors, which is useful for adapting data to varied business requirements.

It could be seamlessly integrated with modern Python web frameworks including FastAPI, Litestar, and Django-ninja.
Documentation
- Documentation: https://allmonday.github.io/pydantic-resolve/
- Demo: https://github.com/allmonday/pydantic-resolve-demo
- Composition-Oriented Pattern: https://github.com/allmonday/composition-oriented-development-pattern
- Resolver Pattern: A Better Alternative to GraphQL in BFF (api-integration).
FastAPI Voyager
For FastAPI developers, we can visualize the dependencies of schemas by installing fastapi-voyager
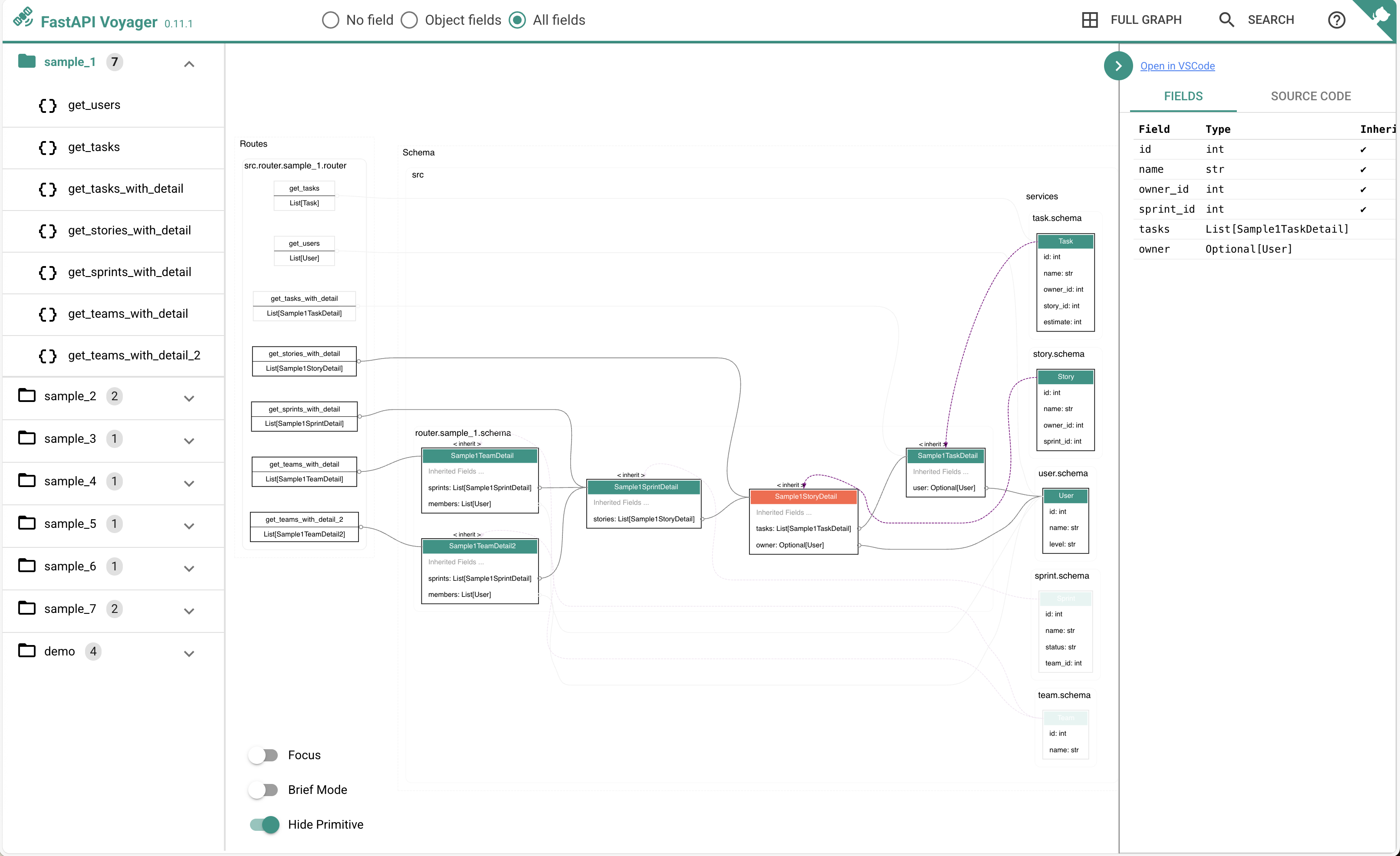
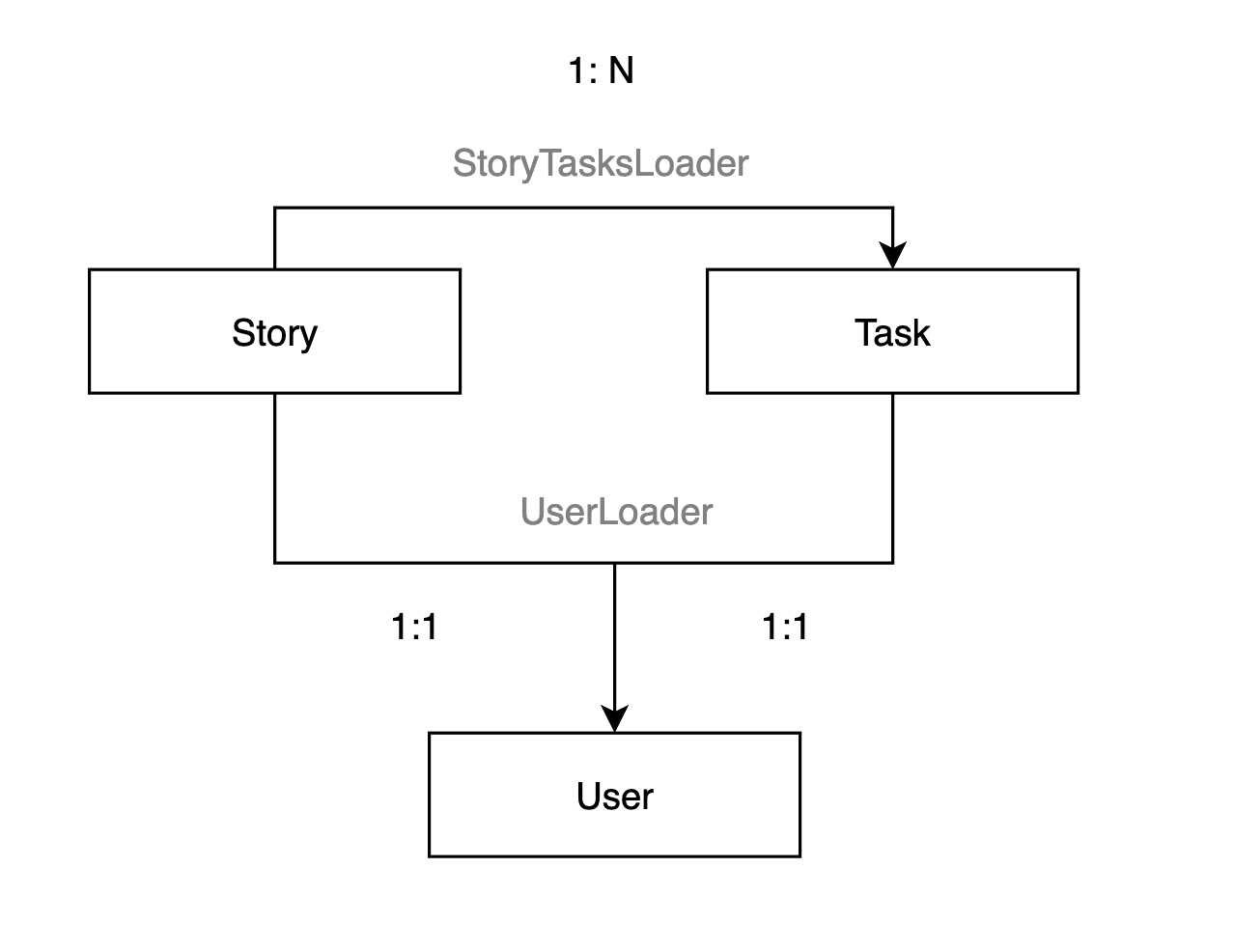
Demo: constructing complicated data in 3 steps
Let's take Agile's model for example, it includes Story, Task and User, here is a live demo and source code
1. Define Domain Models
Establish entity relationships model based on business concept.
which is stable, serves as architectural blueprint
from pydantic import BaseModel
class Story(BaseModel):
id: int
name: str
owner_id: int
sprint_id: int
model_config = ConfigDict(from_attributes=True)
class Task(BaseModel):
id: int
name: str
owner_id: int
story_id: int
estimate: int
model_config = ConfigDict(from_attributes=True)
class User(BaseModel):
id: int
name: str
level: str
model_config = ConfigDict(from_attributes=True)
The dataloader is defined for general usage, if other approach such as ORM relationship is available, it can be easily replaced. DataLoader's implementation supports all kinds of data sources, from database queries to microservice RPC calls.
from .model import Task
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy import select
import src.db as db
from pydantic_resolve import build_list
# --------- user_id -> user ----------
async def batch_get_users_by_ids(session: AsyncSession, user_ids: list[int]):
users = (await session.execute(select(User).where(User.id.in_(user_ids)))).scalars().all()
return users
async def user_batch_loader(user_ids: list[int]):
async with db.async_session() as session:
users = await batch_get_users_by_ids(session, user_ids)
return build_object(users, user_ids, lambda u: u.id)
# ---------- task id -> task ------------
async def batch_get_tasks_by_ids(session: AsyncSession, story_ids: list[int]):
users = (await session.execute(select(Task).where(Task.story_id.in_(story_ids)))).scalars().all()
return users
async def story_to_task_loader(story_ids: list[int]):
async with db.async_session() as session:
tasks = await batch_get_tasks_by_ids(session, story_ids)
return build_list(tasks, story_ids, lambda u: u.story_id)
from V2, ErDiagram can help declare the entity relationships
diagram = ErDiagram(
configs=[
ErConfig(
kls=Story,
relationships=[
Relationship( field='id', target_kls=list[Task], loader=task_loader.story_to_task_loader),
Relationship( field='owner_id', target_kls=User, loader=user_loader.user_batch_loader)
]
),
ErConfig(
kls=Task,
relationships=[
Relationship( field='owner_id', target_kls=User, loader=user_loader.user_batch_loader)
]
)
]
)
config_global_resolver(diagram) # inject into Resolver
2. Compose Business Models
Based on a our business logic, create domain-specific data structures through schemas and relationship dataloader
We just need to extend tasks, assignee and reporter for Story, and extend user for Task
Extending new fields is dynamic, depends on business requirement, however the relationships / loaders are restricted by the definition in step 1.
If ErDiagram is not provided, you need to manually choose the loader
class Task(BaseTask):
user: Optional[BaseUser] = None
def resolve_user(self, loader=Loader(user_batch_loader)):
return loader.load(self.owner_id) if self.owner_id else None
class Story(BaseStory):
tasks: list[Task] = []
def resolve_tasks(self, loader=Loader(story_to_task_loader)):
return loader.load(self.id)
assignee: Optional[BaseUser] = None
def resolve_assignee(self, loader=Loader(user_batch_loader)):
return loader.load(self.owner_id) if self.owner_id else None
If ErDiagram is provided, you just need to provide the name of foreign key
class Task(BaseTask):
user: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
class Story(BaseStory):
tasks: Annotated[list[Task], LoadBy('id')] = []
assignee: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
ensure_subset decorator is a helper function which ensures the target class's fields (without default value) are strictly subset of class in parameter.
@ensure_subset(BaseStory)
class Story1(BaseModel):
id: int
name: str
owner_id: int
# sprint_id: int # ignore some fields
model_config = ConfigDict(from_attributes=True)
tasks: list[Task1] = []
def resolve_tasks(self, loader=Loader(story_to_task_loader)):
return loader.load(self.id)
assignee: Optional[BaseUser] = None
def resolve_assignee(self, loader=Loader(user_batch_loader)):
return loader.load(self.owner_id) if self.owner_id else None
V2 provides a new choice, meta class DefineSubset
class Story1(DefineSubset):
# define the base class and fields wanted
__pydantic_resolve_subset__ = (BaseStory, ('id', 'name', 'owner_id'))
tasks: Annotated[list[Task1], LoadBy('id')] = []
assignee: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
Once this combination is stable, you can consider optimizing with specialized queries to replace DataLoader for enhanced performance, such as ORM's join relationship
3. Implement View Model Transformations
Dataset from data-persistent layer can not meet all requirements for view model, adding extra computed fields or adjusting current data is very common.
post_method is what you need, it is triggered after all descendant nodes are resolved.
It could read fields from ancestor, collect fields from descendants or modify the data fetched by resolve method.
Let's show them case by case, we'll show code in ErDiagram mode.
#1: Collect items from descendants
view in voyager, double click Task1, choose source code
__pydantic_resolve_collect__ can collect fields from current node and then send them to ancestor node who declared related_users.
class Task1(BaseTask):
__pydantic_resolve_collect__ = {'user': 'related_users'} # Propagate user to collector: 'related_users'
user: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
class Story1(DefineSubset):
__pydantic_resolve_subset__ = (BaseStory, ('id', 'name', 'owner_id'))
tasks: Annotated[list[Task1], LoadBy('id')] = []
assignee: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
related_users: list[BaseUser] = []
def post_related_users(self, collector=Collector(alias='related_users')):
return collector.values()
#2: Compute extra fields from current data
view in voyager, double click Story2
post methods are executed after all resolve_methods are resolved, so we can use it to calculate extra fields.
class Task2(BaseTask):
user: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
class Story2(DefineSubset):
__pydantic_resolve_subset__ = (BaseStory, ('id', 'name', 'owner_id'))
tasks: Annotated[list[Task2], LoadBy('id')] = []
assignee: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
total_estimate: int = 0
def post_total_estimate(self):
return sum(task.estimate for task in self.tasks)
#3: Propagate ancestor data to descendants through ancestor_context
view in voyager, double click Story3
__pydantic_resolve_expose__ could expose specific fields from current node to it's descendant.
alias_names should be global unique inside root node.
descendant nodes could read the value with ancestor_context[alias_name].
# post case 1
class Task3(BaseTask):
user: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
fullname: str = ''
def post_fullname(self, ancestor_context): # Access story.name from parent context
return f'{ancestor_context["story_name"]} - {self.name}'
class Story3(DefineSubset):
__pydantic_resolve_subset__ = (BaseStory, ('id', 'name', 'owner_id'))
__pydantic_resolve_expose__ = {'name': 'story_name'}
tasks: Annotated[list[Task3], LoadBy('id')] = []
assignee: Annotated[Optional[BaseUser], LoadBy('owner_id')] = None
4. Execute Resolver().resolve()
from pydantic_resolve import Resolver
stories = [Story(**s) for s in await query_stories()]
data = await Resolver().resolve(stories)
query_stories() returns BaseStory list, after we transformed it into Story, resolve and post fields are initialized as default value, after Resolver().resolve() finished, all these fields will be resolved and post-processed to what we expected.
Testing and Coverage
tox
tox -e coverage
python -m http.server
Current test coverage: 97%
Community
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pydantic_resolve-2.2.4.tar.gz.
File metadata
- Download URL: pydantic_resolve-2.2.4.tar.gz
- Upload date:
- Size: 33.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.4 Linux/6.6.87.2-microsoft-standard-WSL2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c711f33887228f9db22301422b6e3b3d77ff053d565fa19d11890f5fd8a17903
|
|
| MD5 |
42aa5d06c19270975216b28d527dcb1b
|
|
| BLAKE2b-256 |
0de60f9dd0422d03790911491dc421a67ddc215e0a0ec944568bf1eff08c98fe
|
File details
Details for the file pydantic_resolve-2.2.4-py3-none-any.whl.
File metadata
- Download URL: pydantic_resolve-2.2.4-py3-none-any.whl
- Upload date:
- Size: 35.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.4 Linux/6.6.87.2-microsoft-standard-WSL2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
06694f7126d9c4f6004b0707e05c6df59d96af9a4937e86b2e1bd5ad9ea31521
|
|
| MD5 |
d48ac1b9835aaa9de55e27993e1829b7
|
|
| BLAKE2b-256 |
633f76bd936d25168b2d169254b1395ea3631d47ecc3489b3178d073324807cc
|







