BLACKBOX AI is now a @Microsoft Official Partner.
Enterprises can purchase @blackboxai licenses directly through the Microsoft Marketplace.
Built for teams that ship fast and stay secure.
BLACKBOX AI is Live at @VivaTech 2026.
Claude Code, Codex, Grok Build and more agents. Running 24/7. No prompting needed.
Just set your max number of tasks you want done and agents will fix bugs, fix security issues, build new features
All of this is powered by the Agents
New Release: Recursive Self Improving Code
Claude Code, Codex, Grok Build and more agents. Running 24/7. No prompting needed.
Just set your max number of tasks you want done and agents will fix bugs, fix security issues, build new features
All of this is powered by the Agents
New Release: Recursive Self Improving Code
Claude Code, Codex, Grok Build and more agents. Running 24/7. No prompting needed.
Just set your max number of tasks you want done and agents will fix bugs, fix security issues, build new features
All of this is powered by the Agents
Blackbox Agents API - Grok, Claude, Codex, Gemini, All CLI's managed from one API
With the same API you can run Evals on all popular benchmarks like swe-bench, hle, aime, mmlu-pro
With the Blackbox Agents API, the first Recursive Self Improving Repo works 24/7 up to your max
Blackbox Agents API - Grok, Claude, Codex, Gemini, All CLI's managed from one API
With the same API you can run Evals on all popular benchmarks like swe-bench, hle, aime, mmlu-pro
With the Blackbox Agents API, the first Recursive Self Improving Repo works 24/7 up to your max
We’re live at London Tech Week 🇬🇧
See agentic inference live at the BLACKBOX AI booth.
Don’t miss Richard on Tuesday 9th, 12:30 at the Core Stage:
“The Secure Orchestration Layer for the Agentic Enterprise.”
Meet us there.
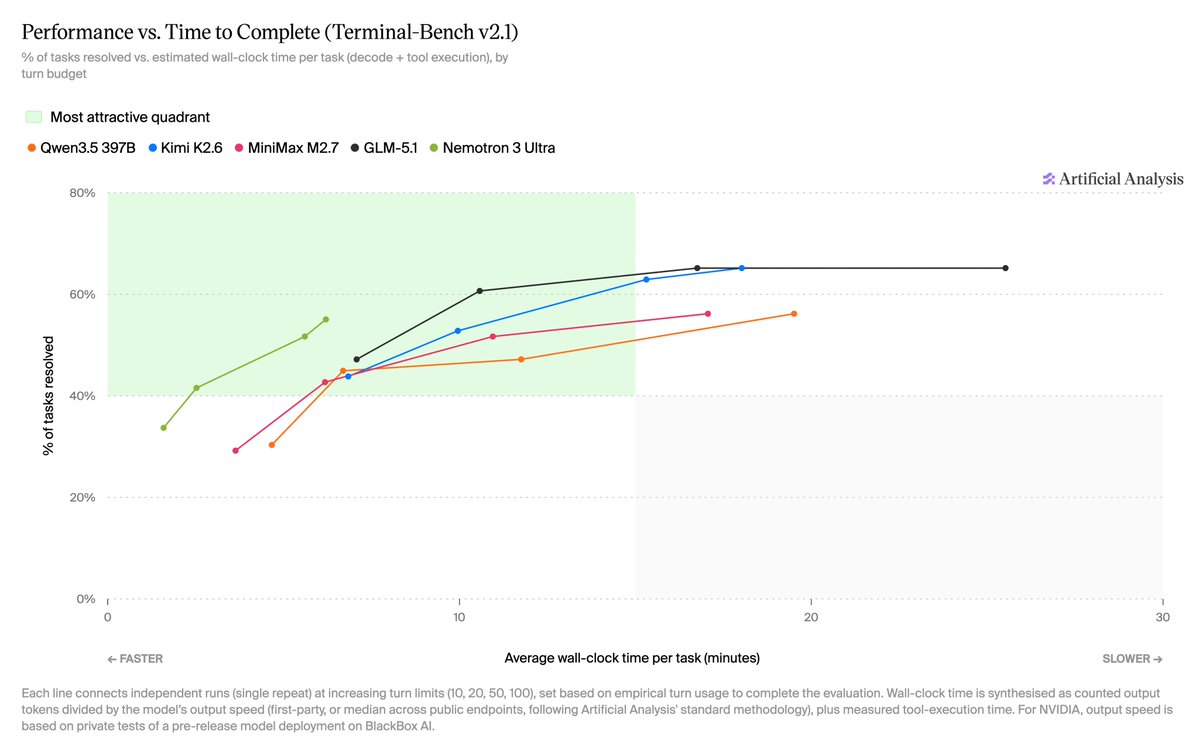
Introducing NVIDIA Nemotron 3 Ultra.
A frontier smart open model built for long-running agents that need to plan, reason, use tools and keep working across complex coding, research and enterprise workflows.
Up to 5x faster inference and up to 30% lower cost for agentic tasks.
We partnered with @nvidia as their single flagship provider and optimized Nemotron 3 Ultra to the highest inference speed served today at 420 output tokens/sec
Nemotron 3 Ultra was launched today, including a focus on low latency agentic performance. We tested it against peers under restricted turn-usage limits on Terminal-Bench v2.1 - @nvidia Nemotron 3 Ultra completes tasks at a much faster pace than peers due to its high inference