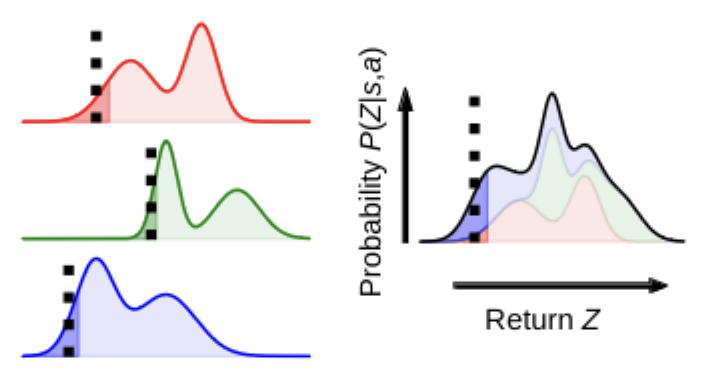
R1's RL findings are great news for reasoning but grim for robotics. All the major takeaways (ground-truth reward, great base models, grouped rollouts from same initial state, sample-inefficient on-policy algos) are really hard to translate to the physical world.