Pinned

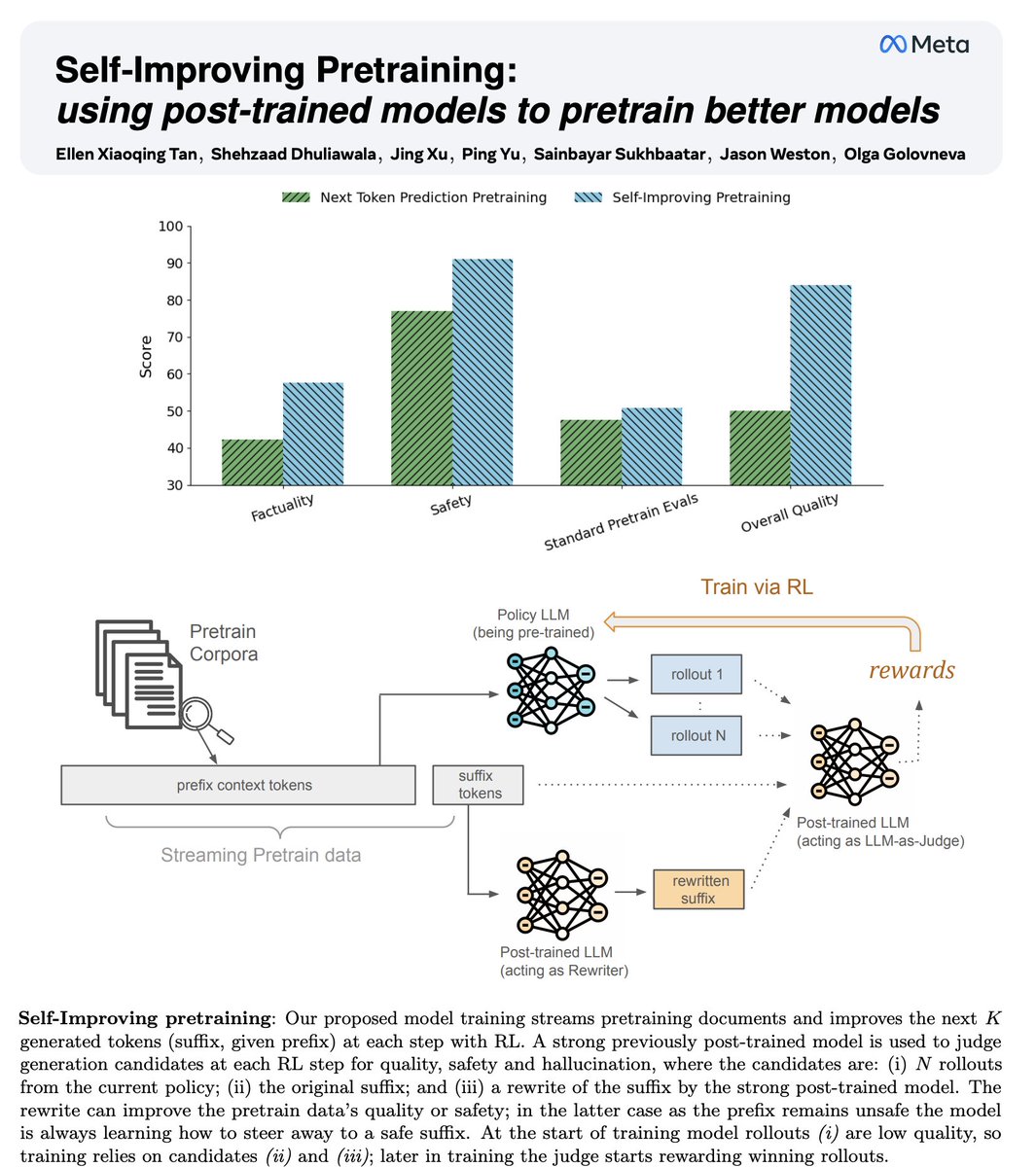
While others claim to do RL in pretraining, we actually did it :) To fix safety, factually, hallucinations at *pretraining* we ensure the model is trained to generate only high-quality safe tokens, even for unsafe/corrupted prompts.

📈Self-Improving Pretraining 📈
✍️: arxiv.org/abs/2601.21343
Reinvents pretraining: no more next token prediction!
- Uses existing LM from last self-improvement iteration to give rewards to pretrain new model on *sequences*
- Large gains in factuality, safety & quality
🧵1/5