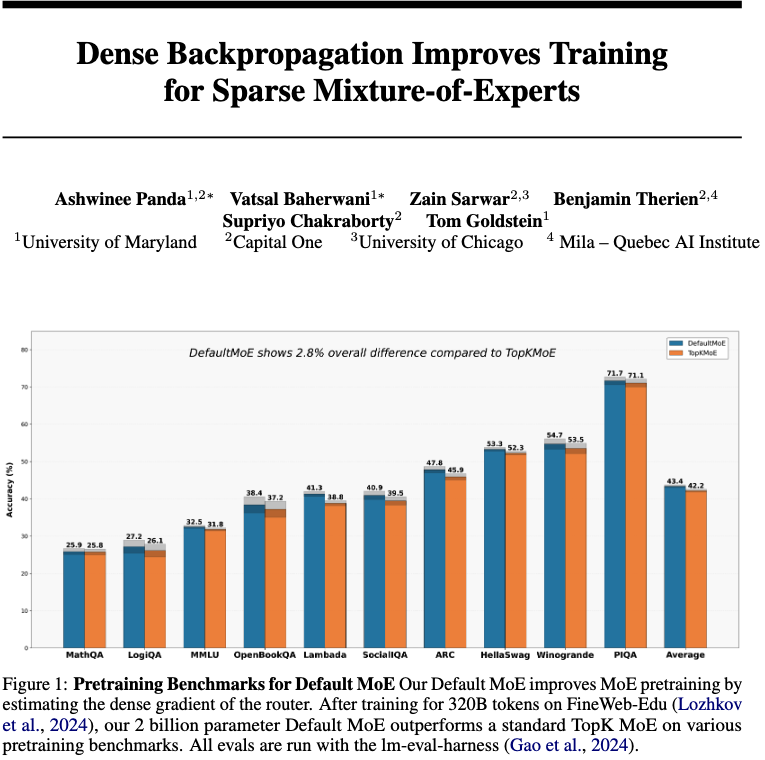
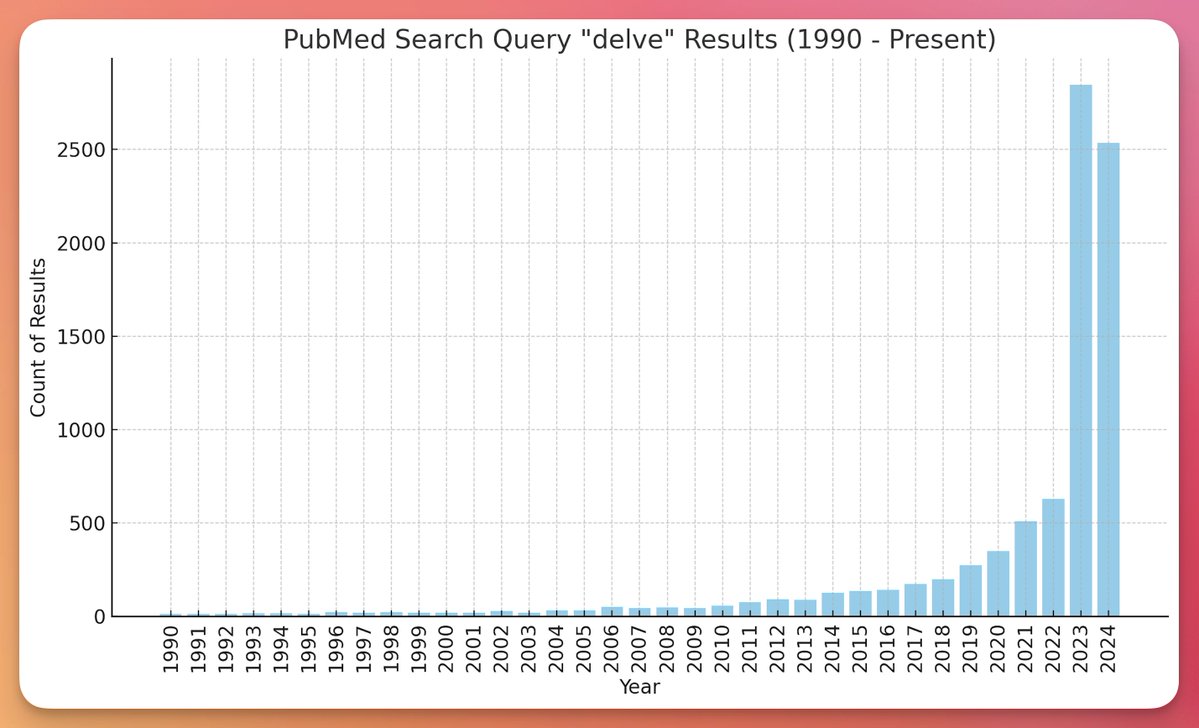
This photo from Carlini’s talk goes incredibly hard. Sometimes it’s difficult to explain to folks who haven’t worked in security/privacy just how challenging it is to build things with robust performance. AI privsec is the “graveyard of papers”.
Pic creds to @furongh