
Shalev
2,376 posts

Shalev
@Shalev_lif
do androids dream of electric sheep? building something new, prev @VectorInst @UofT | co-creator of STEVE-1, Multi-Agent Verification
Joined September 2017
- The neural network objective function is a very complicated objective function. It's very non convex, and there are no mathematical guarantees whatsoever about its success. And so if you were to speak to somebody who studies optimization from a theoretical point of view, they

- Replying to @NTFabianoThis research was funded by the international organization of first born children
- A new replication of DeepSeek's RL results! Here are my notes and some quick thoughts: Method: - Uses PPO instead of GRPO (DeepSeek-R1), still works - Data is 8K (query, final answer) examples from MATH - Rule-based reward modelling (no neural reward) - Initialize model to


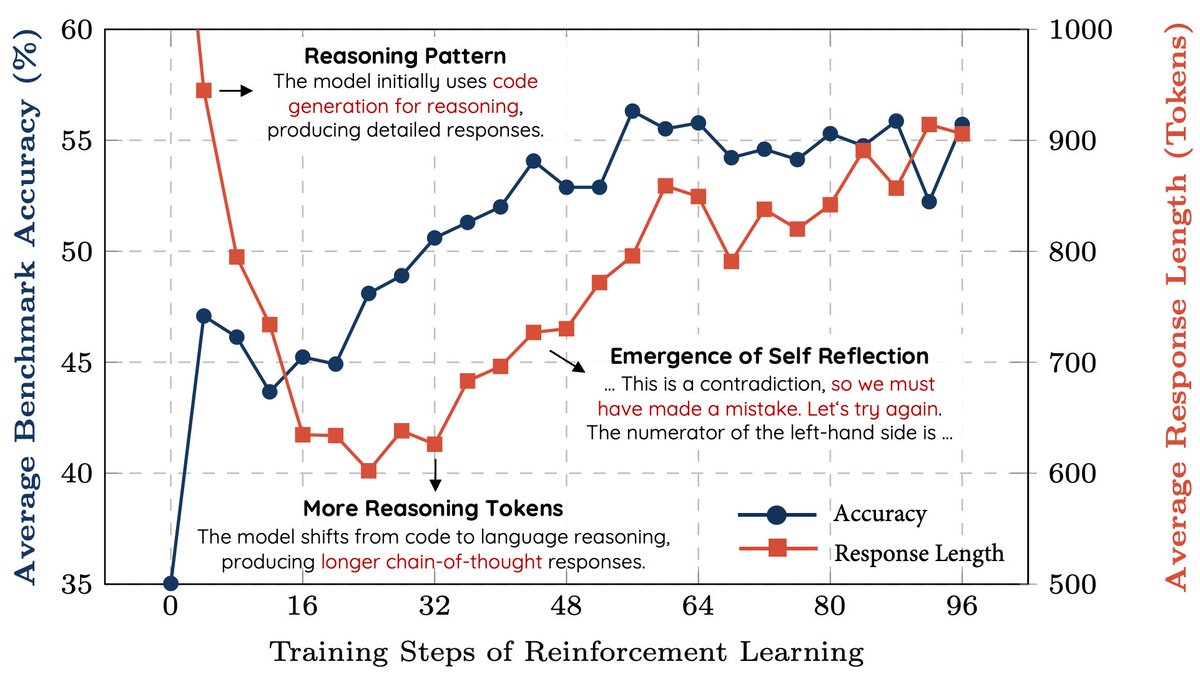 We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly strong. 🚀 Starting from Qwen2.5-Math-7B (base model), we perform RL on it directly. No SFT, no reward model, just 8K MATH examples for verification, the
We replicated the DeepSeek-R1-Zero and DeepSeek-R1 training on 7B model with only 8K examples, the results are surprisingly strong. 🚀 Starting from Qwen2.5-Math-7B (base model), we perform RL on it directly. No SFT, no reward model, just 8K MATH examples for verification, the - Great to see @geoffreyhinton at the @VectorInst office today. Here @michaelrzhang is presenting his work on qualitative eval of LLMs! Very cool to have a Nobel Laureate + Turing Award winner around the campus.

- My question to @ilyasut at NeurIPS 2024: Do LLMs generalize multi-hop reasoning out-of-distribution?
 00:00
00:00 - Hot off the Servers 🔥💻 --- we’ve found a new approach for scaling test-time compute! Multi-Agent Verification (MAV) scales the number of verifier models at test-time, which boosts LLM performance without any additional training. Now we can scale along two dimensions: by

- Absolutely stacked panel at the System-2 Reasoning at Scale workshop at NeurIPS with Josh Tenenbaum, @MelMitchell1, @fchollet, @jaseweston, @DBahdanau, @dawnsongtweets, and @Yoshua_Bengio (with @nouhadziri moderating). An amazing end to the conference. Will add notes below.

- Replying to @ns123abcUh, she’s a third-year PhD. Many of the most influential papers in AI have been written by PhD students… Also, a paper is written by a team. The first author usually did most of the actual work during the project (ie, writing the code, running the experiments, etc.).
- Replying to @karpathyThis reminds me of a meme @_jasonwei posted a while back! That is, once you play with these models so much you kind of develop your own mini test suite to gain intuition of its performance.

- @ilyasut giving a talk at the NeurIPS 2024 Test of Time awards! Will add more photos below, throughout the talk.

- Replying to @Shalev_lif
- In a few years PhDs won’t be coding much. They’ll have a fleet of agents coding up, running, and tuning their experiments. At that time, the most valuable skill will be deep expertise, as suggested by @RogerGrosse.Replying to @roydanroy and @tunguzIn all seriousness, PhDs today will have tools so powerful that previous generations won’t know what to think of them. I think it is the most exciting time to be working. Just don’t work in an old way.
- 🥳 Great news! Our paper STEVE-1 has been accepted at #NeurIPS 2023 as a spotlight! I'm so proud to have worked on this project with my amazing collaborators @keirp1 @SirrahChan @jimmybajimmyba @SheilaMcIlraith ✈️ Very excited to present our work in New Orleans! ✈️ Project
 00:00
00:00



