In the final post of the Adaptive RAG series, we explore how to treat selective retrieval as a core, learned skill, moving from passive observation to active, intelligent decision-making.
Is Cosine-Similarity of Embeddings Really About Similarity?
Netflix cautions against blindly using cosine similarity as a measure of semantic similarity between learned embeddings, as it can yield arbitrary and meaningless results.
📝arxiv.org/abs/2403.05440
RAG Does Not Work for Enterprises
Explores the challenges and requirements for implementing RAG in enterprises proposing potential solutions like semantic search and hybrid queries, and an evaluation framework to validate enterprise-grade RAG solutions
📝arxiv.org/abs/2406.04369
On the Theoretical Limitations of Embedding-Based Retrieval
@orionweller et al. at Google DeepMind demonstrate that vector embeddings have fundamental limitations in representing all possible document combinations.
📝arxiv.org/abs/2508.21038
👨🏽💻github.com/google-deepmin…
Foundations of Vector Retrieval
This 185-page monograph provides a summary of major algorithmic milestones in the vector retrieval literature, with the goal of serving as a self-contained reference for new and established researchers.
📝arxiv.org/abs/2401.09350
Small Language Models (SLMs) Can Still Pack a Punch: A survey
Amazon presents a survey of Small Language Models (1-8B parameters), exploring how these smaller models can match or outperform larger counterparts.
📝arxiv.org/abs/2501.05465
Semantic Retrieval at Walmart
Presents a hybrid search system deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries, significantly improving relevance.
📝
FastRAG: Retrieval Augmented Generation for Semi-structured Data
Introduces a RAG approach that improves data processing speed up to 90% and reduces costs by 85% compared to GraphRAG through schema and script learning techniques.
arxiv.org/abs/2411.13773
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Introduces a two-stage RL approach enabling LLMs to autonomously invoke search during reasoning.
📝arxiv.org/abs/2503.05592
👨🏽💻github.com/SsmallSong/R1-…
Understanding LLM Embeddings for Regression
Demonstrates that LLM embeddings can outperform traditional feature engineering for high-dimensional regression tasks while preserving Lipschitz continuity in the embedding space.
arxiv.org/abs/2411.14708
WARP: An Efficient Engine for Multi-Vector Retrieval
Introduces an efficient engine that significantly reduces query latency for multi-vector retrieval systems through implicit decompression and dynamic similarity imputation.
📝arxiv.org/abs/2501.17788
👨🏽💻github.com/jlscheerer/xtr…
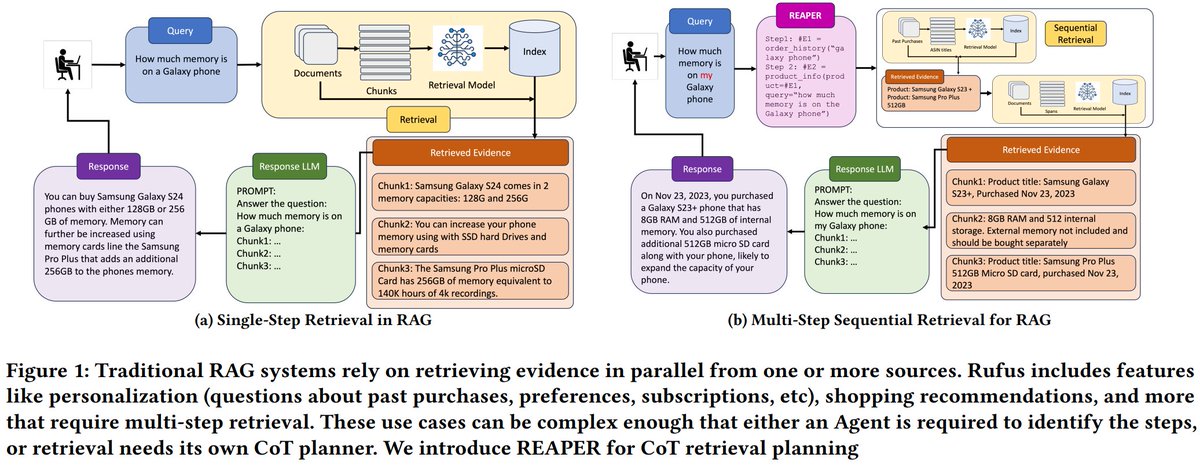
REAPER: Reasoning based Retrieval Planning for Complex RAG Systems
Amazon presents an LLM-based planner for generating efficient retrieval plans in conversational AI systems offering reduced latency, higher accuracy, and easy scalability.
📝arxiv.org/abs/2407.18553
A Survey on LLM-as-a-Judge
Presents a comprehensive survey examining how to build reliable LLM-as-Judge systems, exploring strategies for improving consistency, mitigating biases, and adapting to diverse assessment scenarios.
📝arxiv.org/abs/2411.15594
👨🏽💻github.com/IDEA-FinAI/LLM…
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
Salesforces presents a survey of LLM alignment methods, categorizing approaches into four main topics and identifying future research directions.
📝arxiv.org/abs/2407.16216