Major life update: I'm joining @AnthropicAI this week! Looking forward to meeting and working with the amazing team there!
I’m beyond thankful for an amazing 2 years with my colleagues and collaborators at @AiEleuther .
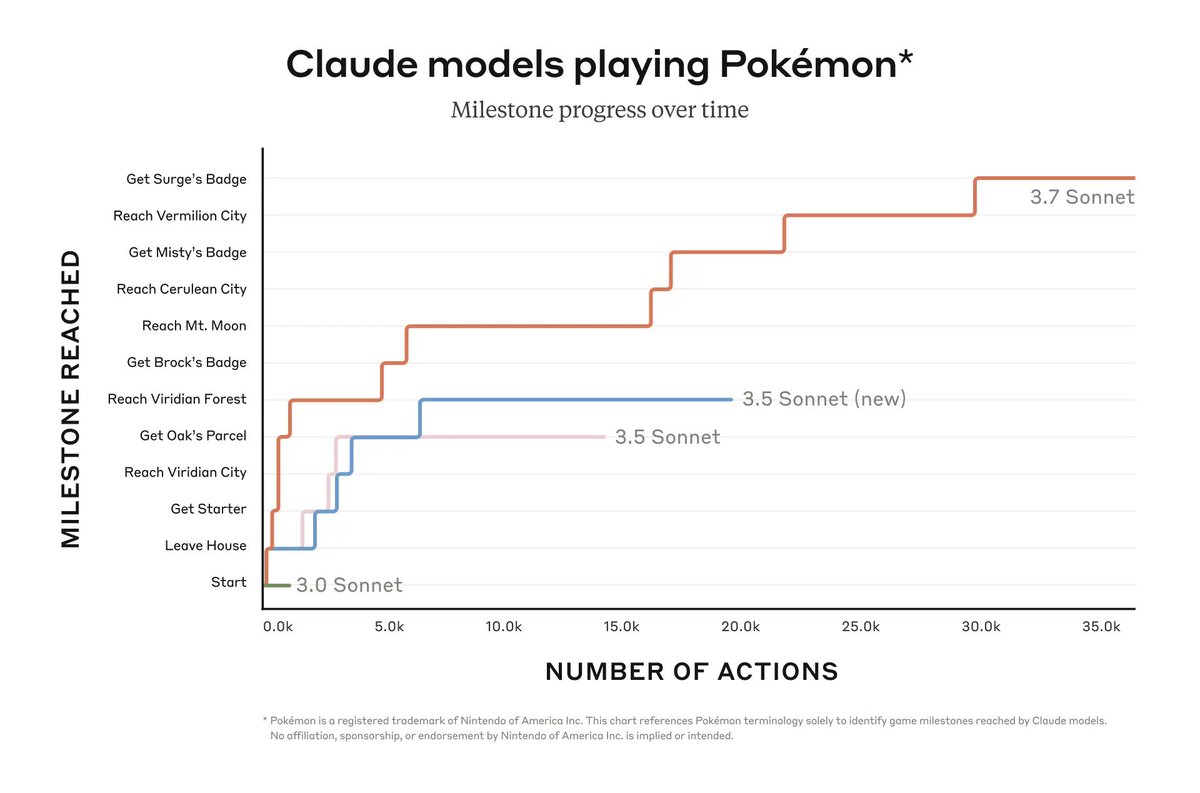
Claude 3.7 Sonnet is a significant upgrade over its predecessor. Extended thinking mode gives the model an additional boost in math, physics, instruction-following, coding, and many other tasks.
In addition, API users have precise control over how long the model can think for.
Excited to announce our paper Pythia: A Suite for Analyzing LLMs across Training and Scaling has been accepted as an Oral paper at #ICML2023 ! arxiv.org/abs/2304.01373
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4.
Claude Opus 4 is our most powerful model yet, and the world’s best coding model.
Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
My favorite bit in this paper:
I and @bbrabbasi wrote an appendix formalizing what is done evaluating models with loglikelihood multiple choice and perplexity evals.
afaik, none of this has been written up in one place in most papers and just been tacitly assumed before!
Excited to share our new paper, Lessons From The Trenches on Reproducible Evaluation of Language Models!
In it, we discuss common challenges we’ve faced evaluating LMs, and how our library the Evaluation Harness is designed to mitigate them 🧵
arxiv.org/abs/2405.14782
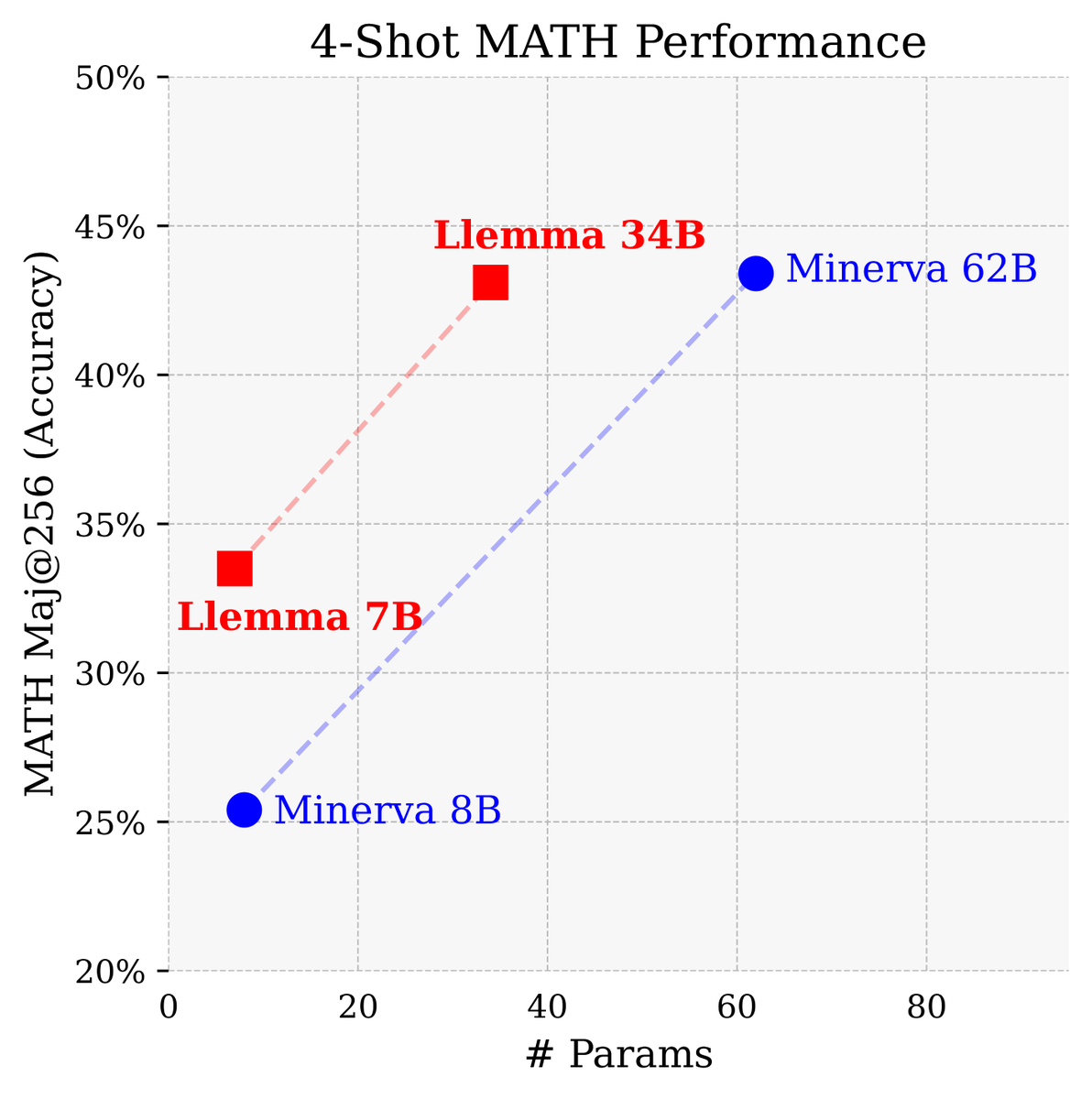
Beyond excited for our work on Llemma to finally be public!!
We trained very strong general math LMs (7B > Minerva 8B, 34B ~= Minerva 62B) and released them + training, eval, analysis code!
Can’t wait to see the math+AI field pick these up for future developments in the open.
We release Llemma: open LMs for math trained on up to 200B tokens of mathematical text.
The performance of Llemma 34B approaches Google's Minerva 62B despite having half the parameters.
Models/data/code: github.com/EleutherAI/mat…
Paper: arxiv.org/abs/2310.10631
More ⬇️
This proposal suggests a global moratorium on training runs > 10^24 flops—approximately that used by llama 2-70B,
and 100x lower than the EO reporting threshold.
Just astoundingly absurd
The AI Summit consensus is clear: it's time for international measures. Here is a concrete proposal.
In our recent paper, @jasonhausenloy , Claire Dennis and I propose an international institution to address extinction risk from AI: MAGIC, a Multinational AGI Consortium.
so, it turns out i am the top solo user for downloads on HF (thanks solely to my lm-eval MMLU mirror! 😅)
now is probably a good time to express how grateful i am for the users, contributors, and community around the LM Evaluation Harness! :’)
We’ve released the paper for Pythia, a set of LLMs designed to facilitate scientific study on LLMs and their training data!
So excited to have this out finally! Read more here:
Have you ever wanted to do an experiment on LLMs and found that none of the existing model suites met your needs? At @AiEleuther we got tired of this happening and so designed a model suite that centers enabling scientific research as its primary goal
arxiv.org/abs/2304.01373