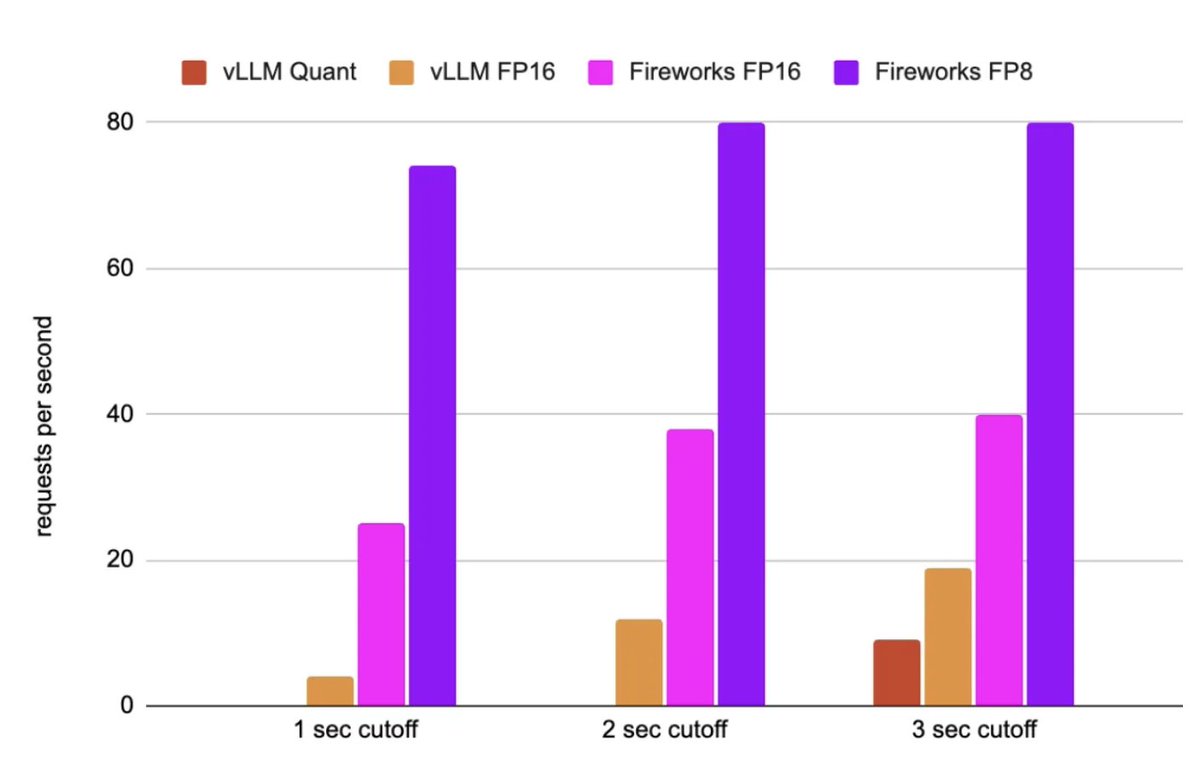
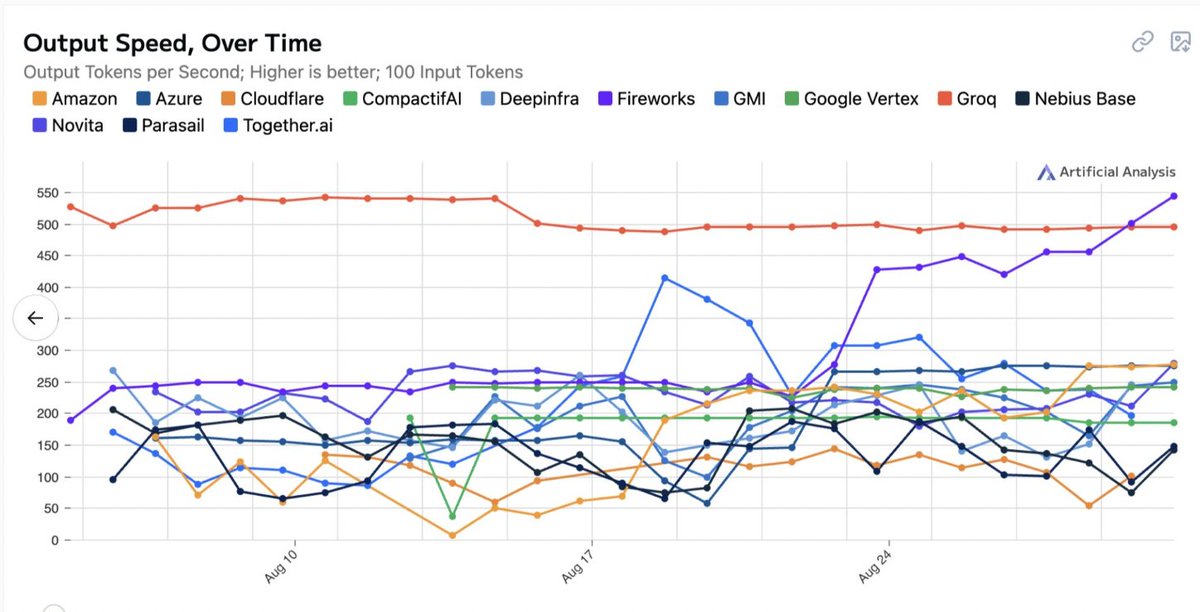
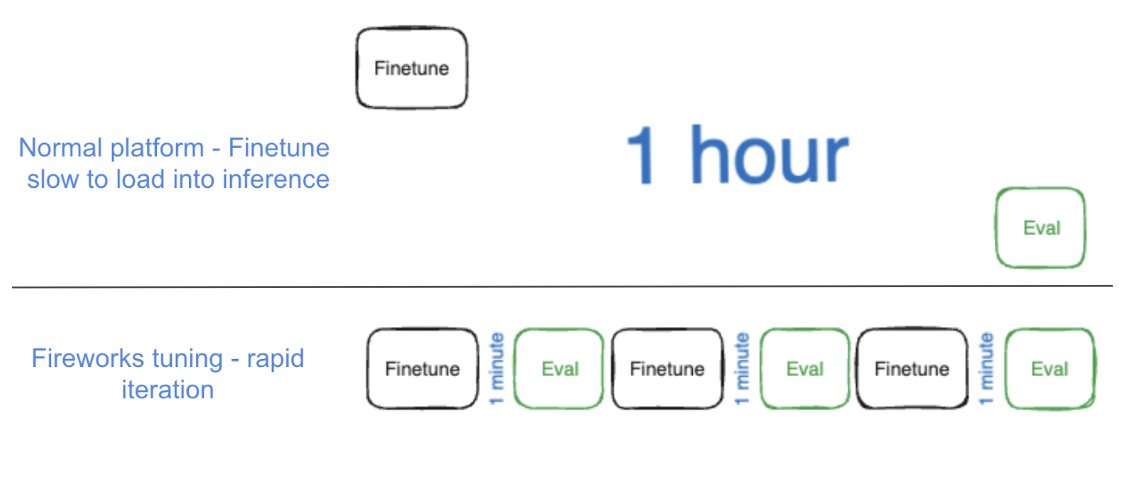
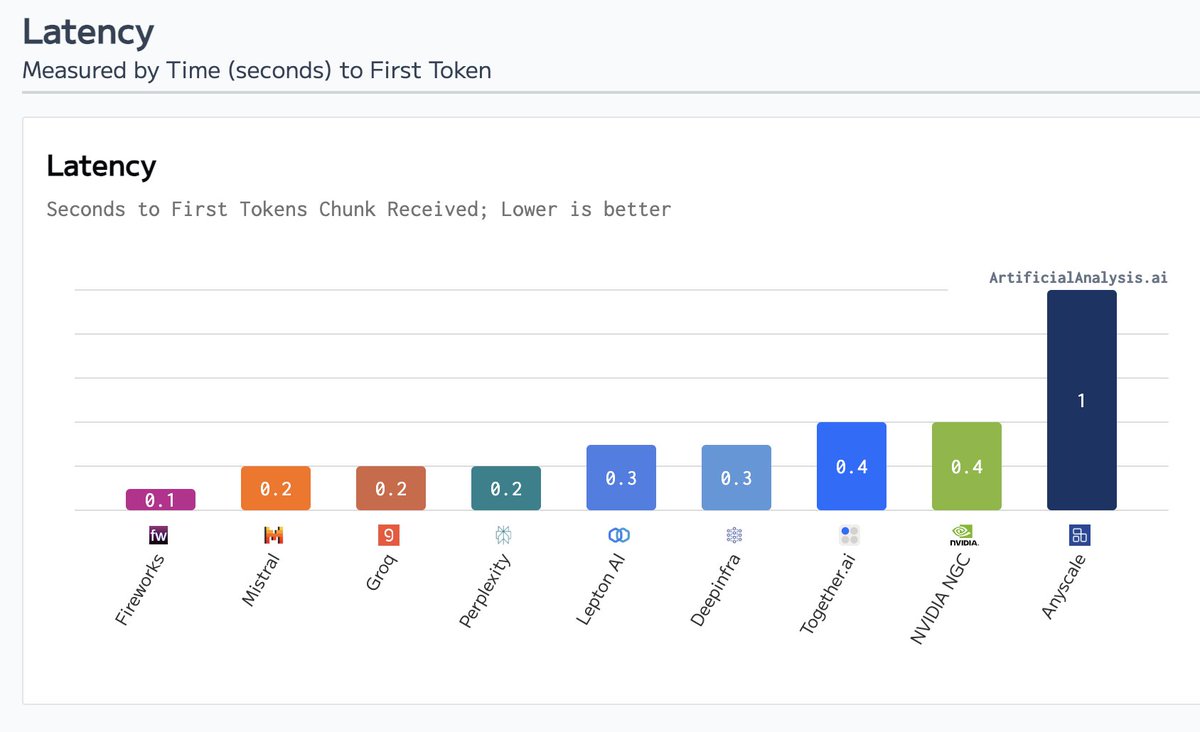
Fireworks AI has raised $52M in Series B funding led by @sequoia !
This round propels our mission to enhance our inference platform and lead the shift to compound AI systems. Huge thanks to our investors @nvidia , @AMD , @MongoDB , @benchmark , Sheryl Sandberg , Frank