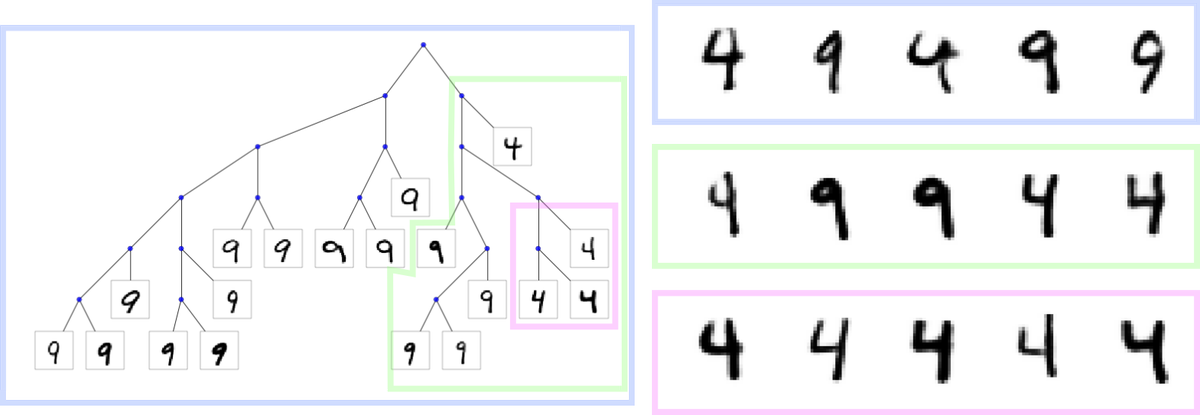
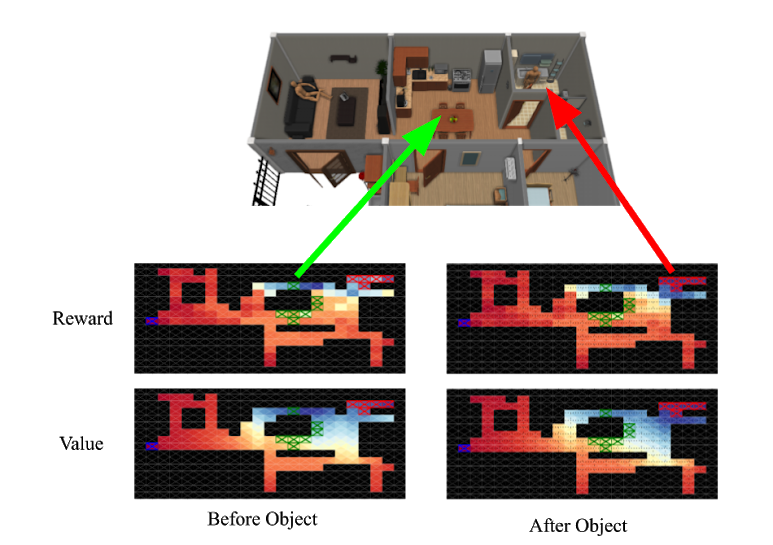
Pinned

Built with JAX!


Introducing Gemini 1.0, our most capable and general AI model yet. Built natively to be multimodal, it’s the first step in our Gemini-era of models. Gemini is optimized in three sizes - Ultra, Pro, and Nano
Gemini Ultra’s performance exceeds current state-of-the-art results on