Pinned
Trevor Gale
238 posts

Trevor Gale
@Tgale96
Research Scientist @ Google DeepMind | Former Stanford CS
Maine, USA
Joined April 2013
 I woke up to an interesting PR in MegaBlocks this morning... 😅magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce RELEASE a6bbd9affe0c2725c1b7410d66833e24github.comSupport new model by pierrestock · Pull Request #45 · databricks/megablocks
I woke up to an interesting PR in MegaBlocks this morning... 😅magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce RELEASE a6bbd9affe0c2725c1b7410d66833e24github.comSupport new model by pierrestock · Pull Request #45 · databricks/megablocks- Want to run a sparse neural network at warp speed?🔥 The code from our paper is now open-source! We’ve released our sparse models, tuned code and our dataset of sparse matrices: github.com/google-researc…
- 🧵We’re excited to announce MegaBlocks, our system for efficient “dropless” MoE training! 🤖 MegaBlocks outperforms Tutel by up to 40% by reformulating MoEs as block-sparse operations, which allows us to avoid token dropping without sacrificing hardware efficiency 🚀.

- Replying to @Tgale96I’m not done with MegaBlocks 😁 @apaszke @epiqueras1 @sharadvikram and I just dropped something we’ve been working on for a bit yesterday. MegaBlocks + JAX + TPU = MegaBlox 🔥
- Look how much fun we're all having together! Come MegaBlock with us! 🥰 github.com/stanford-futur…

- Replying to @jefrankle and @arthurmenschDon't fight guys we can all use MegaBlocks together 🥹
- What stands between us and widespread use of sparsity in deep learning? I tried to organize some of my thoughts for this @sigarch blog post!
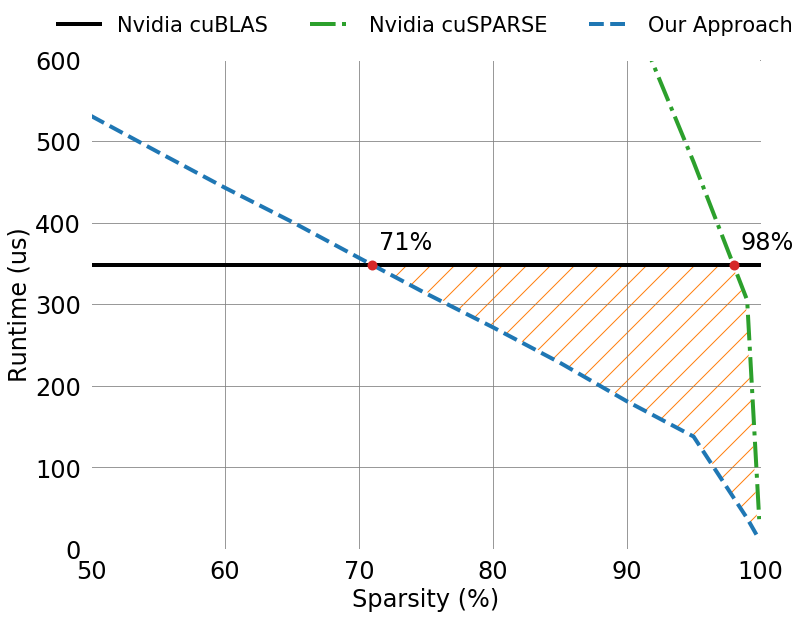
- Excited to share something I've been working on for a while! Fast GPU kernels for sparse linear ops with @erich_elsen, Cliff Young and @matei_zaharia! With some fancy tricks, sparse ops can be faster than dense at as low as 71% sparsity 🔥 arxiv.org/abs/2006.10901
- “But to us a “register” is a 16x16 tile of data.” Sounds like you guys might like TPUs 😁 Very fun post to read!(1/7) Happy mother’s day! We think what the mothers of America really want is a Flash Attention implementation that’s just 100 lines of code and 30% faster, and we’re happy to provide. We're excited to introduce ThunderKittens (TK), a simple DSL embedded within CUDA that makes

- Seems like pretty marginal quality gains from scaling parameter count by ~3x. 35 days on 3360 A100s, so maybe between $3M and $8M to train? Not sure this model makes sense to train, at least for these applications... developer.nvidia.com/blog/using-dee…
- Submit your work to the all new “Sparsity in Neural Networks” workshop! We have an excellent speaker lineup and attendance is free. Hope to see you all there 😁NEW WORKSHOP: Sparsity in Neural Networks: Advancing Understanding and Practice (July 8-9, 2021). This workshop will bring together members of the many communities working on neural network sparsity to share their perspectives and the latest cutting-edge research (Deadline: 6/15)

- Replying to @ml_hardware @abhi_venigalla and 2 othersThe Megatron paper did tell us to do this (5.1). Probably not the only trick we should steal from Megatron-LM 😁
- Replying to @Tgale96Oh, and also a text from Mihir with this screenshot 😂"pierrestock changed the title Mixtral-8x7B support Support new model 6 hours ago"









