Pinned

🔥Two things I'm esp excited about 5.4:
1. Unification: we merged our codex & mainline models
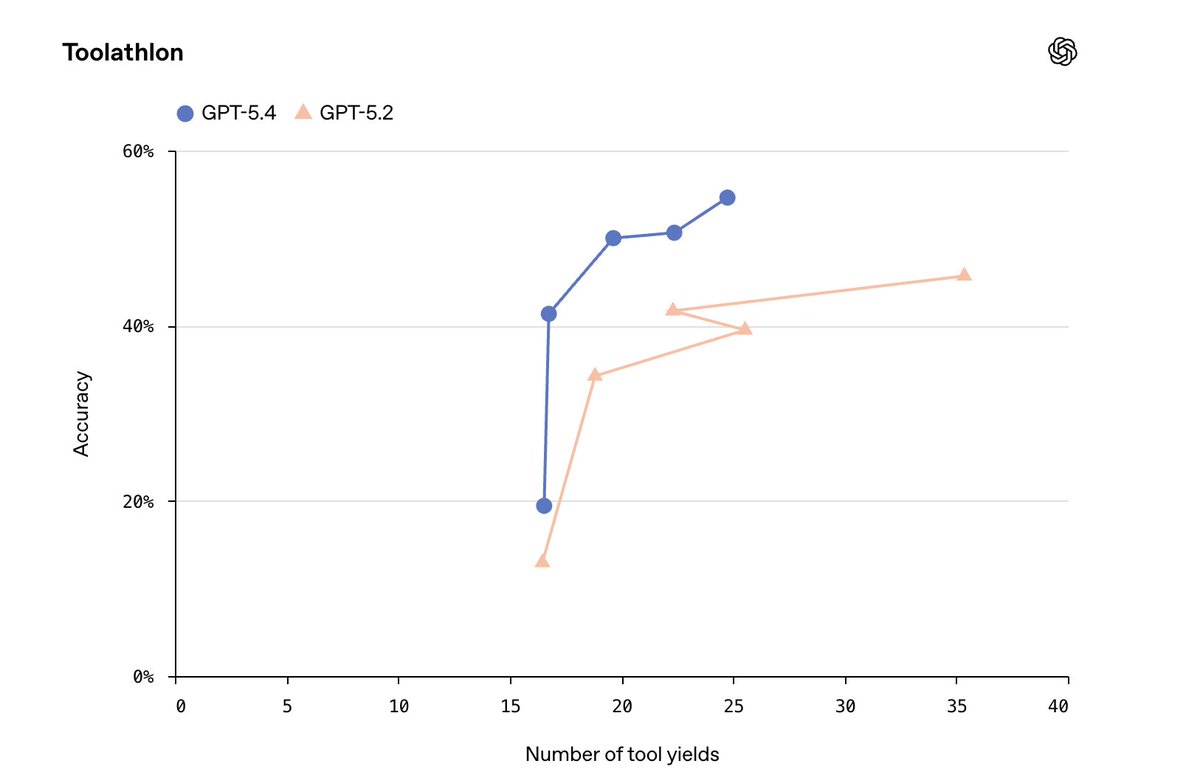
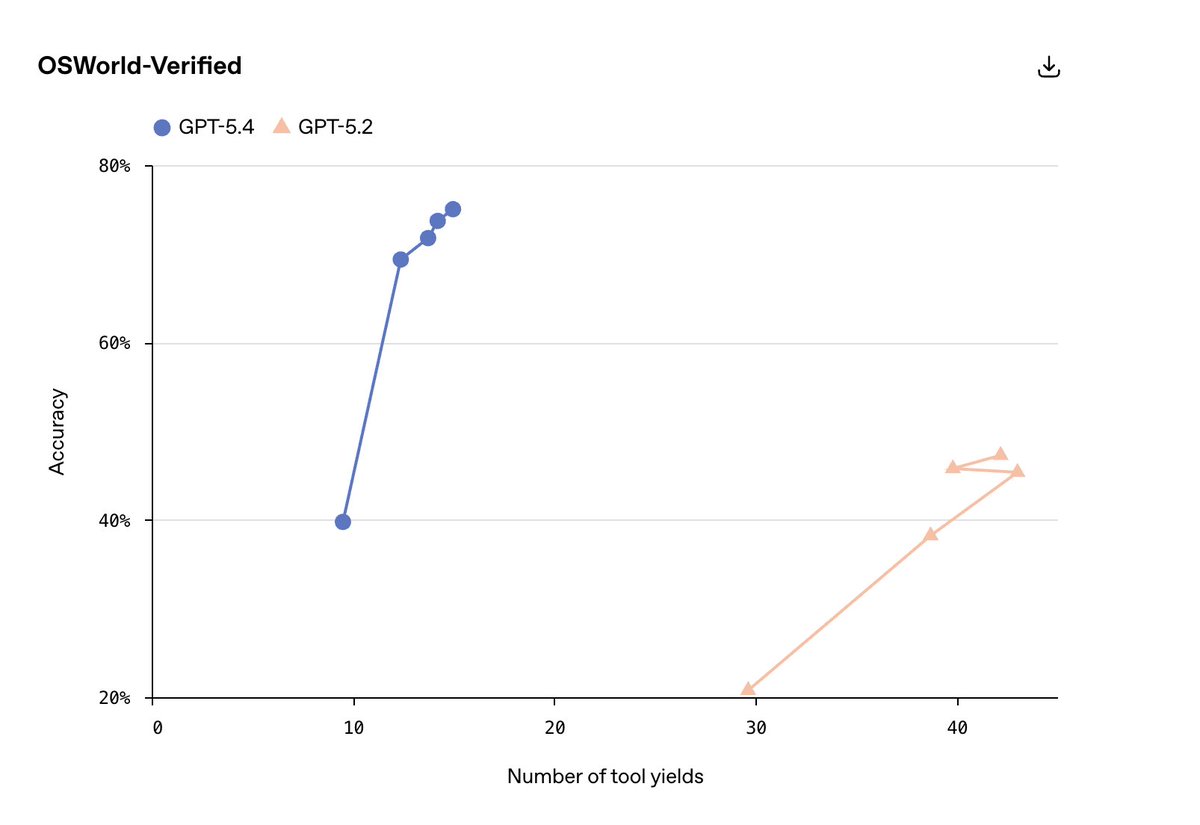
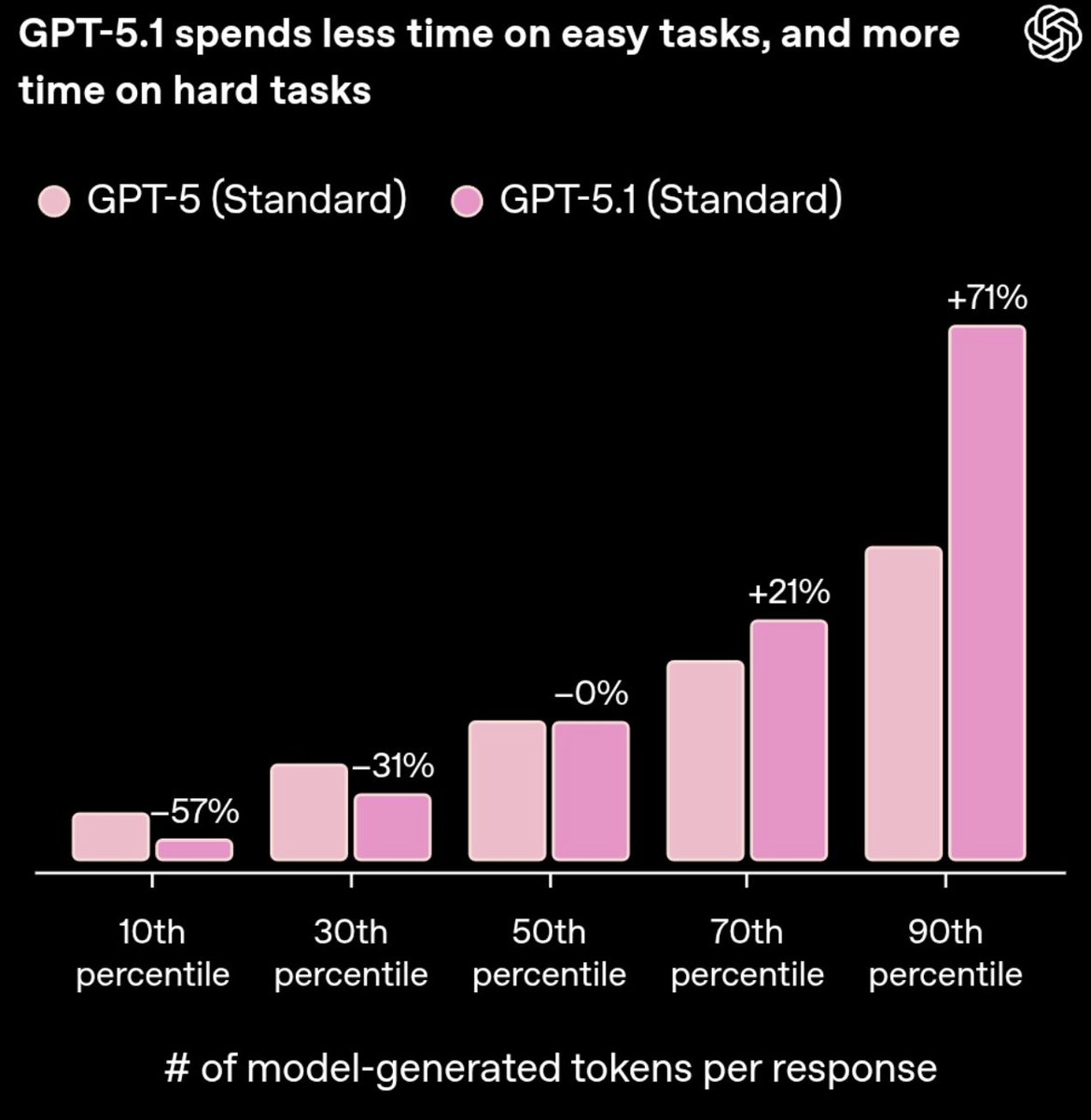
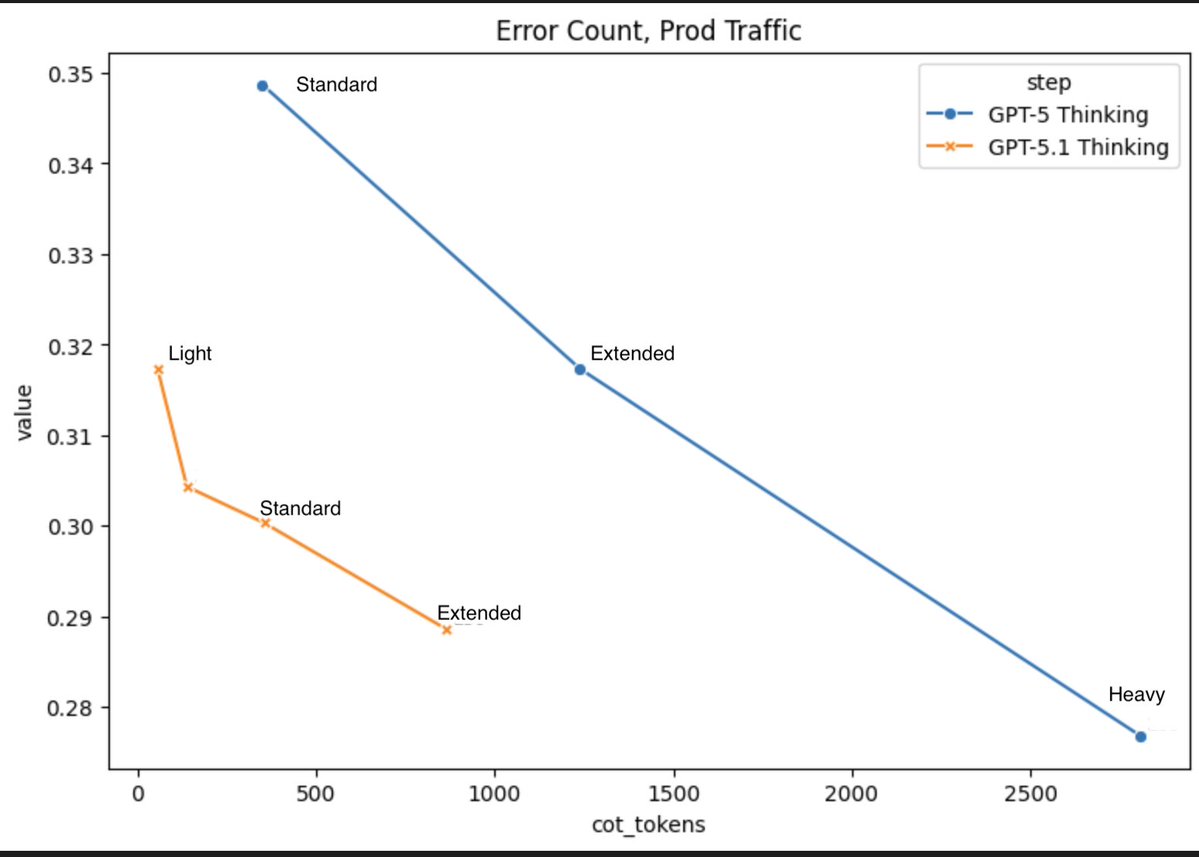
2. Efficiency: we brought the efficiency of 5.3-codex to CUA & knowledge work. We only showed 3 such plots in the blog but many of our evals required less time (tokens/tools) than 5.2.